《两周自制脚本语言》笔记 2——语法分析和 BNF
程序被分割为 Token 后,下一步是根据 Token 序列构造抽象语法树(AST 或 ASTree,Abstract Syntax Tree),这一步称为语法分析。语法分析的任务是分析 Token 间关系,比如判断 Token 所属表达式和语句,处理标识符的配对等,同时会检查程序是否存在语法错误。
语法,BNF
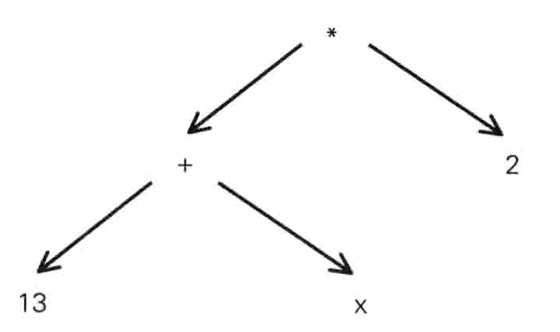
抽象语法树的结构如何,已经无需再提。任何节点都是操作符,任何叶子都是值。
比如(13 + x) * 2),能得到(* (+ 13 x) 2)这样一个树,其图形化表述如下。可以看到,一切根结点都是操作符/函数之类,一切叶节点都是值(也可以是函数)。
语言处理器(即将源代码转换为可执行程序的程序)为了构造抽象语法树,需要按照特定规则将 Token 序列读入,这种规则就是程序设计语言的语法(syntax)。
语法通过** BNF(Backus-Naur Form,巴科斯范式)进行表述。其将规定 Token 的组合规则。比如,双目运算符要由表达式,操作符,表达式组成。比如 while 要由 while 关键字,表达式,语句块组成。BNF 与上下文无关文法等价**。
下面代码展示了一个提供四则运算,整型字面量以及括号的语法的 BNF,其使用了 BNF 的扩展版本 EBNF——
1 | |
BNF 中,冒号左侧称为元变量或非终结符,右侧为一个用于匹配的模式,其通过元符号,终结符以及非终结符进行表示。左侧内容和右侧等价,即左侧的非终结符转化成右边的模式。终结符代表预先定义的 Token,比如上面的”(“,”)”,NUMBER,“+”。上面的|,(),{}等都是元符号,其具有特定语义,能够对模式进行丰富的表达,就像正则表达式中的。*?+|之类。下面给出各元符号的语义——
| 元符号 | 语义 |
|---|---|
| { pat } | 模式 pat 出现 0 次或更多次 |
| [ pat ] | 模式 pat 出现 0 次或 1 次 |
| pat1 | pat 2 | 匹配 pat1 或 pat2。|的优先级是最低的——即其最后执行,就像一道厚障壁 w |
| ( … ) | 将括号中内容识别为一个模式 |
最初的 BNF 似乎无法使用{}的样子,因此只能使用|和 () 来进行递归定义,比如 expression 可以表述成为——
(应有误,这种 BNF 对 LL(1) 是完成不了的)expression: term | term ("+" | "-") expression
比如,有一个表达式——
1 | |
词法分析后得到这样的 Token 序列(当然,这里的”+”和”*”都是标识符)。
1 | |
下面给出其匹配流程——
1 | |
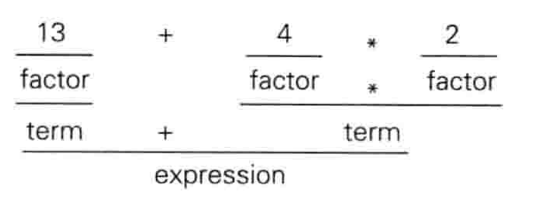
书中将 factor 称为因子,term 称为项,expression 称为表达式。可以注意到,这里已经体现出四则运算的优先级了。但是也可以通过其他方式对优先级进行处理。
于是,可以根据这样的语法分析的结果构造抽象语法树——
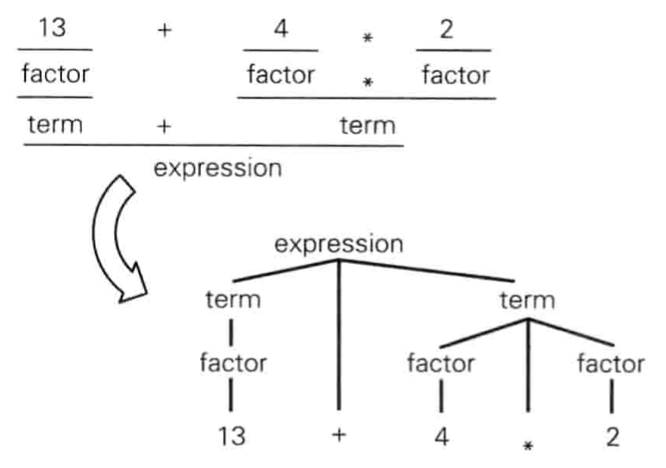
就记录到这里。下一步是学习一下语法分析的各种算法,以及一个 LL(1) 语法分析器的手动编写。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!