《两周自制脚本语言》笔记 1——基于正则表达式的词法分析

该书的目标是使用 Java 语言实现一门简单的脚本语言——更具体的来说,是实现一个简单的脚本语言的语言处理器,其主体是一个解释器(就像 python),但内部通过编译器提高性能。
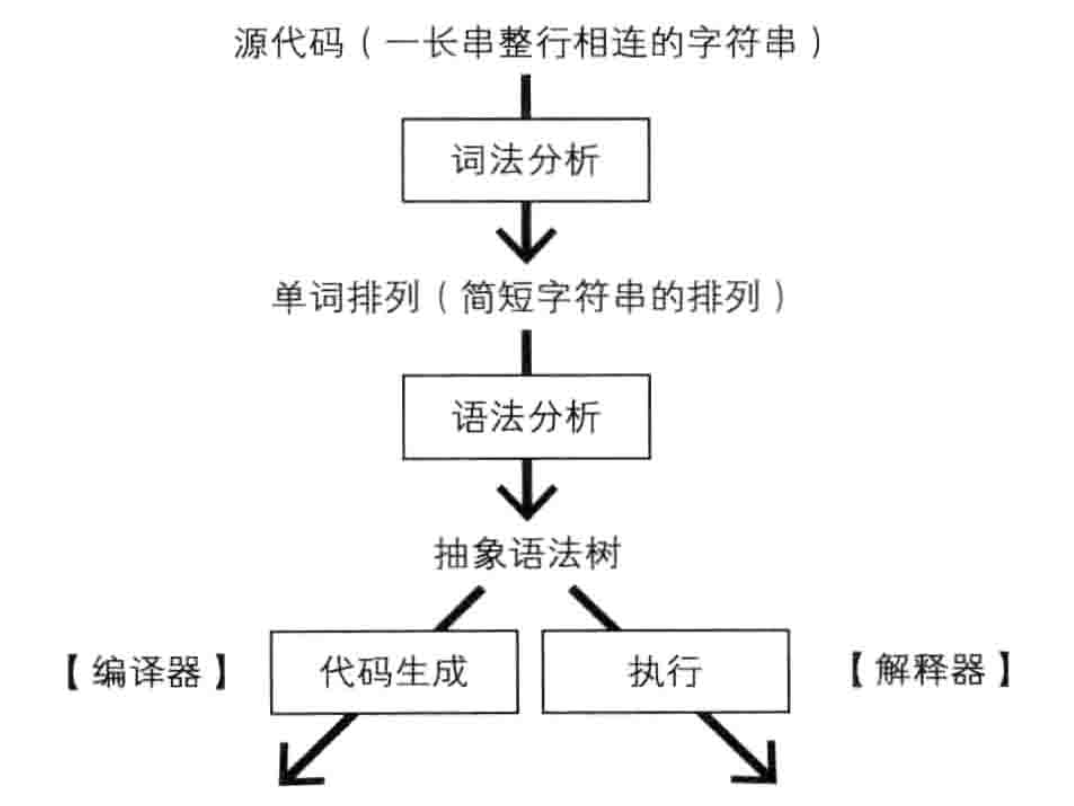
该语言处理器的大体流程和编译原理课上的所学大同小异——先将源代码通过词法分析转换成 Token 序列,再将 Token 通过语法分析生成抽象语法树(AST),再通过编译器或解释器对语法树进行编译或执行。
AST 是什么?联想 Lisp 罢!
该书将此语言命名为 Stone——Perl 是珍珠(大概),Ruby 是红宝石,而它则只是一颗小石子。
等什么时候我真的去写一门喜欢的语言,就自己给它取名吧。
Stone 的基本语法
Stone 仍旧是 C 系语言,它在某些地方和 python 相近,某些地方又同传统的语言相近——
1 | |
语句的换行如果要能够允许各种情况,会导致实现的复杂化,因此对换行情况做尽量多限制——左花括号必须不换行,else 必须和右花括号在同一行。
如果强制要求除代码块以外,语句必须以分号结束,实现会变得容易,但是这并不现代。
Stone 语言要求 if 和 while 的语句体必须使用花括号包括——这导致 else if 是不合法的!可以模仿 python,使用类似 elif 的关键字来实现 else if。
如果之后有条件,我想为其提供一些我喜欢的特性,比如一切皆表达式,尾 lambda……
词法分析
Token
词法分析是语言处理器的第一个组成部分,其负责将源代码(也就是保存在文本文件里的,符合特定规范的一长串字符串)进行切割,划分为多个子字符串,生成相应** Token**。
比如if i == "me" {这样一行代码,其将会被拆分成"if" "i" "==" ""me"" "{",空白和注释都会被去除。
Token 当然不能是简单的 String 对象,其要保存更多信息,包括但不限于 Token 的值,类型,行号等。每个 Token 类型都需要被小心定义,规定怎样的字符串才能合法构成特定类型 Token。
Stone 语言定义 Token 有三种类型——标识符(Identifier),数字(Number),字符串(String)。
标识符代表变量名,函数名,类名等,运算符以及各种括号,标点符号也属于标识符。数字和字符串都通过字面量进行表示。考虑到 Stone 对换行是比较敏感的,换行符也为标识符。
似乎有时候(或者是一般来说?)保留字(关键字)和标点符号会被归为另一种类型的 Token。
1 | |
Token 的定义
下面给 Token 一个总的定义——
1 | |
关于 Token 的定义(即规定各个类型 Token 的合法值),使用 java 的正则表达式的库并遵循其定义方式——
首先是最简单的数字的字面量——[0-9]+(没错,这里没有小数!负数则通过负号运算符进行定义……大概吧)。
然后是关于标识符的定义,首先是关于保留字,变量,函数,类的命名,其必须使用大写或小写字母,下划线开头,只能出现数字和字母,下划线——[A-Z_a-z][A-Z_a-z0-9]*。
然后则是各种标点符号,其包括==,<=,>=,&&,||等双字节的符号,也包括更多单字节符号,其为==|<=|>=|&&|\|\||\p{Punct},这里的\p{Punct}表示与任意符号字符匹配。因此关于标识符的总的正则表达式为[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\|\||\p{Punct}。
然后是字符串字面量的定义,其为"(\\"|\\\\|\\n|[^"\n])*",这代表字符串中的值能包括、",\\,\n(作为字面量写出来的,两个字符的、n,而非真正的换行符),以及除”,换行符以外其他字符(”和换行符会打断字符串。书中居然没有匹配换行符,为什么?)。
Java 需要对”和、进行转义,最终编写在 Java 文件里的正则表达式如下。需要记住的是,下面的字符串最后应当得到的目标字符串是上面的正则,因此这其中有字面量 Java 字符串->实际正则表达式字符串这一层转换——比如正则表达式要匹配\n这个回车符,对应 Java 代码就要\\n,其将成为原生字符串\n并作为 regex。但若是要匹配\n这个长度为二的字符串,相应的原生字符串是\\n,为此,相应的 Java 字符串应当转义两个反斜杠,最终得到\\\\n这样的结果。
如果 Java 提供了 raw 字符串的功能,编写这个将漂亮很多。
1 | |
词法分析器的设计和实现
Java 语言能够使用一个正则表达式获取特定字符串中所有匹配字符串,因此这里使用正则表达式来获取 Token,具体来说,可以通过如下正则表达式来对 Token 进行获取——
1 | |
这里的 pat3 的括号加或不加都可,只不过标识符所匹配的括号不一样罢了。
其中,pat1-3 为匹配整型字面量,字符串字面量,标识符的正则表达式。//. *用于匹配注释,\s *用于匹配 0 个及以上的空字符,? 代表即使没有任何内容也能够匹配。正则表达式匹配成功时,能通过代码对每个括号所匹配的内容进行获取,这样从四个括号的匹配值是否是 null 就能看出,能获得到被匹配的 Token 的类型。
词法分析器的工作是简单的——逐行读取源代码,对每行源代码,从开头起检查内容是否匹配,并在检查完成后获取所有匹配的字符串。
在获取时,使用的正则表达式如下。
1 | |
根据正则表达式,能够容易写出相应的代码,下面的是获取单行的 Token 的代码——
1 | |

正则表达式用来进行词法分析感觉还是有些不太舒服的,好在实践中已经开发了许多现成的词法分析器可以直接使用,该书似乎之后还会通过有限状态自动机来进行词法分析…再议吧!下一步是学习和编写语法分析器。
感觉其实可以把 NumToken 和 StringToken 统一起来,变成 LiteralToken
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!