Hive 学习笔记 1——架构,DDL 和数据的导出导入
下面的笔记基本上是根据尚硅谷的视频做的,回过头来看看,这样学习的效率是很低的,之后要避免这种手册式的学习和笔记。考虑之后对常用子句多记录一些示例。
Form is liberating。
Hive 就是一种用于构造 MapReduce 的 DSL 及相关基础设施,这样的概括大概足矣。
Hive 的文档见 此。
突然想到,在之前写业务代码的时候,我基本不会去关心代码的性能(至少不会关注常数级的性能),对人的可读性比对机器的可读性更重要;但在大数据领域上这就不一样了——大数据所写的代码,很可能将会被应用上千万次,这时候任何一点常数倍的复杂度的差别就会引起很大的性能问题,
为什么是 Hive
Hadoop 的一个重要的原则就是数据本地性——我们移动计算到数据,而非移动数据到计算,从而减少网络 IO,增加吞吐量。
移动计算,这点(的字面意思)在 MapReduce 的使用中非常明显——我们把自己的 MapReduce 程序打成 Jar 包,放置到 Hadoop 集群中,并要求它(分发和)运行该 Jar 包,这就是一个典型的“移动计算”的操作了。但这种操作总会让人感觉有点麻烦,即使它可以自动化。
这时候就自然会想,能不能让客户端直接把程序提交给 Hadoop 集群呢?部分可行,可以通过 Hadoop Stream 做这个,但是程序一般来说总有一些自己的依赖,这时候 Hadoop 集群下必须要有相应依赖,这也引入了额外的麻烦,让人想到 JavaEE 的怪味,和当前的容器化是背道而驰的(咱提交 Docker 镜像过去吧 hhh)。
自接触函数式编程伊始,将函数/过程当作数据来看待已经深入我心,但这种抽象仅在同一进程下能够屏蔽掉底层的麻烦细节,倘若想要把过程真的当作数据来序列化,持久到硬盘中,在本地或网络进行传输的话,就会遇到一万个问题,最典型的一个就是上面说的外部依赖问题。
为了不引入额外的依赖,这时候我们就想着,能不能把 Mapper 和 Reducer 的程序形式化,结构化,抽象为一些预先定义的“指令”,从而能够被方便地解析,以及当作对象传输,从而达到目的?
另外,在编写 MapReduce 程序时,也会发现,自己写的 Mapper 和 Reducer 好像在形式上有很多重复,而一些操作实现起来非常繁琐,如JOIN等,但是这些繁琐的操作实际上也能够找出模式来。这时候就会希望,有没有啥东西能把这麻烦的过程给抽象一下呢?
而 Hive 就是这样的一个框架——它是一个解决海量的结构化日志的数据统计工具/数据仓库工具。它模仿 SQL,定义了一种名为 HQL 的 DSL,并能够把用户编写的 HQL 转换成对应的 MapReduce 程序;它将结构化的数据文件映射成为一张表,提供类 SQL 的查询的功能。
为什么是 SQL 呢?可以意识到,SQL 中常用的操作,如 select,where,order by,group,count 等,都是可以使用 map(其实是 flatmap)和 reduce 操作表达的,如 select 是 map,where 是 filter,group,count 是 reduce……
顺带一提,Pig 框架也是和 Hive 一样的思想的产物,但 Pig 使用一种特定的脚本语言,且似乎已经不再流行。
Hive 的特色
优点——
- 语法类 SQL,CRUD 程序员能快速上手(但是数据类型则是类似 Java 的,和其它 SQL 不一样)
- 使能够免去编写 MapReduce 程序的麻烦
- 善于处理大数据(十亿,百亿级),这是传统的 OLTP 数据库做不到的;但处理小数据无优势
- 支持用户自定义函数
缺点——
- HQL 表达能力有限
- 无法表达迭代式算法(SQL 嘛)
- 不擅长数据挖掘
- 效率差
- MapReduce 自动生成的,因而性能很大程度上要仰仗“编译器”的优化,不够智能
- 调优困难
Hive 和 Hadoop 平台紧密结合——Hive 处理的数据存储在 HDFS;Hive 的底层仍旧是 MapReduce(也可以换成 Spark);Hive 通过 Yarn 来执行程序。
Hive 的数据存储在 HDFS,这意味着更新操作是很昂贵的,因此 Hive 不建议修改操作。
Hive 不需要集群部署,只需要一个节点即可,它相较于 Hadoop 集群,更像是一个客户端(但从外部来看,它仍旧是服务端)。
Hive 有自己的元数据——不然它如何把文件和表做映射呢?Hive 的元数据存储在传统的数据库中,它默认使用一种嵌入式的数据库,名为 Derby(爱马仕欢喜),但一般都会使用 MySQL 等在工程实践中常用的数据库来保存。
Hive 的数据仍旧是以比较规范的形式存储在 HDFS 中的——它默认使用/user/hive/warehouse存储所有数据(Hive 的 default 数据库),其中每一张表都作为一个文件夹存放,比如我们创建表create table test (id string),它就会在该目录下创建 test 文件夹;且它是以该文件夹下所有数据作为自己的数据的——如果在该文件夹下创建文件存储和表同样格式的信息,如1001\n1002,它是可以被select查到的,十分有趣(更有趣的是使用 count 查不到,这说明有的操作是通过查询元数据进行的,而有的操作则是通过查询实际数据);这让我们很容易通过 sql 以外的方式对表进行数据插入,但显然需要同时能够对元数据进行维护。
Hive 是读时模式,即在读取数据时才对数据的格式进行验证;而传统数据库是写时模式,即在数据写入时就对数据的格式进行检查。读时模式在加载(LOAD)数据时非常迅速,因为它不对数据进行任何校验操作,直接移动文件即可。
读时模式的优势在于加载迅速,但在查询时则会逊色一些,且难以进行索引等操作(现在有了),但这些其实问题并不大,因为 Hive 的应用场景通常会进行全表扫描,
Hive 的诸服务及其相互关系
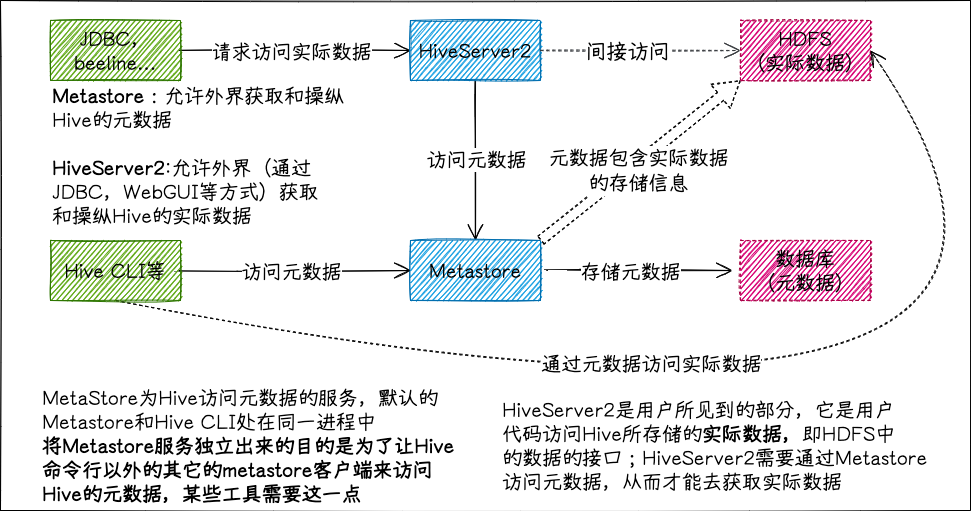
接触最多的将是 hiveserver2,启动该服务能让 Hive 以 Thrift 服务的形式运行,从而让外部 Thrift,JDBC 客户端能进行连接;其次是 metastore,Hive 通过 metastore 来访问保存的元数据,而 metastore 将数据保存在关系型数据库中。
数据类型
HQL 的数据类型比较类似 Java,其有如下数据类型——
- TINYINT,对应 Java 的 byte
- SMALLINT,对应 short
- INT
- BIGINT,对应 long
- BOOLEAN
- FLOAT
- DOUBLE
- DECIMAL,任意精度的有符号数,如 DECIMAL(10, 2) 表示小数点左部 10 位,右部 2 位。
- STRING,同 String,可变长
- TIMESTAMP,时间类型,精度为纳秒,应该对应 Java 的 Datetime
- DATE,日期类型,类似 LocalDate?
- BINARY,对应 byte[],用途应为存储一些二进制数据
还有一些集合数据类型——
- STRUCT,类似 C 的结构体,Java 的 Record,类型的语法形如
STRUCT<data1:INT, data2:STRING> - MAP,键值对的映射,语法形如
MAP<STRING, INT> - ARRAY,语法形如
ARRAY<INT> - UNION,类似 C 的联合体,怀疑它的存在意义
比如,对一个这样的 JSON 串进行建模,相应的语句见下。
1 | |
1 | |
STRUCT 类型通过.来访问字段,MAP 和 ARRAY 通过[]来访问元素,同 js 一致。
插入该表的语句如下。
1 | |
集合类型的字面量
这些语法只有看书才能找到……Hive的文档和社区一言难尽。
集合类型没有提供直接的字面量,都是使用函数来进行表述的,我认为这是很好的设计。
数组的字面量形如array(1, 2),类型需要保证一致。
结构体的字面量形如struct('hello', 1),最终得到的实际的结构体为{"col1":"hello","col2":1},这不一定符合我们的需求,因此还有另一个语法(函数),形如named_struct('name', 'yuuki', 'age', 16),得到{"name":"yuuki","age":16}。
哈希表的字面量形如map('yuuki', 16, 'honoka', 17),各键值对的类型需要保证一致。也有一个函数str_to_map("meowmeow:3,nyanya:2"),该函数能通过字符串构造哈希表,但类型似乎只能是MAP<STRING,STRING>。
DDL
Web 开发里使用 CREATE 之外的 DDL 的机会实际上并不多,因为 Web 开发对表的设计慎之又慎毕竟一改可能就需要改非常多的东西。而大数据的话可能用的情况会稍多些?但是估计也只是仅限于在尾部多加个字段啥的。
DDL(Data Definition Language,数据定义语言),即创建和查询,操作表结构的语言,它相较于 DML 不那么重要。这里尽量把麻烦的语法都写出来,方便之后可以查询。
关于数据库
USE 关键字用于切换使用数据库。
SHOW 关键字用于对表,数据库等信息进行展示,也可用于展示 SQL 语句的实际信息(带上所有参数的)。
比如,创建一个表create table test(id string);,可以使用show create table test;查看建表时的实际语句——
1 | |
CREATE DATABASE 语句创建数据库,语法如下,[]内内容为可选项,大写的单词为关键字,小写为变量。
1 | |
自己创建的数据库默认存在/user/hive/warehouse/DB_NAME.db/,数据库上所有表都将在该文件夹下。但 default 就存在/user/hie/warehouse/下,没有另外建立文件夹。
查询数据库使用 SHOW 关键字,其语法为 SHOW DATABASES [LIKE search_str];,可以使用 like 关键字查询名称符合特定模式的数据库。
查询数据库信息用DESC DATABASE db_name。
修改数据库使用ALTER DATABASE db_name SET DBPROPERTIES('properties_name' = 'properties_value'),只能修改DBPROPERTIES。
删除用DROP DATABASE [IF EXISTS] db_name [CASCADE],DROP 默认只能删除空的数据库,若要删除非空的数据库需要使用 CASCADE 关键字。
表的创建
CREATE 关键字用于创建表,它或许是最重要的 DDL 的关键字了。
下面的语法并非全部,还有更多的未列出(比如上面的建表的示例展示的)
1 | |
EXTERNAL 关键字标识表是外部表,默认的表称为管理表(Managed table),其实应该叫“受管理表。
管理表的特点是,表的元数据的生命周期和实际数据的生命周期一致,也就是说当我们删除一张管理表的时候,存储在 HDFS 上的实际数据也会同时被删除。删除外部表的时候,HDFS 的数据不会被删除。
倘若某数据是同其它系统共享的,应当使用外部表。外部表比管理表更为常用。
使用
ALTER TABLE tb_name SET TBLPROPERTIES("EXTERNAL"="TRUE");设置表为外部表,属性大小写敏感。
使用DESC FORMATTED tb_name查询表的信息。
表的修改,删除
重命名表使用 RENAME TO 关键字,语法为ALTER TABLE tb_name RENAME TO new_name。
修改列的信息主要包括列名和列类型。
更新列的信息使用 CHANGE 关键字,语法为ALTER TABLE tb_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name],注意更新后的类型必须给定。
添加列使用 ADD 关键字,更换列使用 REPLACE 关键字,REPLACE 实际上就是直接把所有列全部换掉了。它们的语法为ALTER TABLE tb_name ADD COLUMNS (col_name column_type [COMMENT col_comment], ...);。
没有删除列的操作,只能使用 REPLACE。
DML
DML(Data Manipulation language,数据操纵语言),即用于对数据库的对象(即实体,即表中的每一行)进行访问的语言,如 SELECT,DELETE,UPDATE 等语句,但 Hive 提供更丰富的操作,以满足各种导入/导出数据等的需求。
数据导入
LOAD 和 INSERT 最为常用。
LOAD(!)
十分明显地,通过手动上传文件到 HDFS 上来插入数据并非是一个好的选择——元数据没有相应改变,这使得某些查询结果会出现错误,而且这样插入数据也无法在插入时得到 Hive 的校验,因此有可能插入格式错误的数据。
通过上传文件来插入数据可以使用所谓的 LOAD 关键字,其语法为LOAD DATA [LOCAL] INPATH 'data_path' [OVERWRITE] INTO TABLE tb_name [PARTITION (partcol1=val1,...)]。
- LOCAL: 表示从本地文件系统加载数据,否则从 HDFS 中加载
- OVERWRITE: 表示覆盖原有数据,或者追加数据
- PARTITION: 关于分区信息的设置
注意!当从 HDFS 中加载数据的时候,它执行的是一种 mv 操作——移动了文件的位置!这种移动是逻辑上的,因为 HDFS 的路径中的文件夹是虚拟的,只是改一下路径即可,因此性能和文件大小无关。
考虑对下面创建的表执行 LOAD 操作——
1 | |
一个插入文件的示例为如下,注意其和表的列格式的配置一致。
1 | |
假设该文件保存在本地文件目录/home/yuuki/data.txt,则相应插入语句为——
1 | |
注意——LOAD 操作没有走 MR 操作,它是直接把文件放到 HDFS 上的相应路径并修改元信息(元数据中的 numfiles 的值),因此操作非常快。插入后再运行select count(*) from student,就会发现该操作跑 MR 而非直接查元数据了。
INSERT(!)
普通的 INSERT 语句不需赘述,但 Hive 提供了一个重要的变体——通过查询结果插入/覆盖数据到表——INSERT (INTO|OVERWRITE TABLE) tb_name select_clause,一个例子是——
1 | |
多个 INSERT 子句可以放置在一起作为单条语句,似乎在分区表中比较常用。
可以使用FROM子句进行插入,示例如下——
1 | |
该操作只会对原表进行一次查询,因而效率更高。
CREATE
CREATE 关键字也有几个能用于建表的同时插入数据的操作,比如CREATE TABLE [IF NOT EXISTS] tb_name AS select_clause语句能够通过查询结果创建表,这和 insert 是类似的,区别在于 insert 是向已有的表进行操作,而该操作是通过数据创建表,表的字段由查询结果决定。
山不去见穆罕默德,穆罕默德就去见山:LOCATION 关键字用于在已有的数据上建表的情况——它会指定表的存储位置,因而倘若该位置已经有数据,就相当于是将这些数据插入到表中了。
IMPORT
IMPORT 需和 EXPORT 配合使用,相当于是把一个表的数据以特定的形式导出,再导入到另一张表,语法为 IMPORT TABLE tb_name FROM path。用处似乎不多。IMPORT 不能使用在已有数据的表中。
数据导出
INSERT
INSERT 也可以用来导出数据,语法为INSERT OVERWRITE [LOCAL] DIRECTORY path [ROW FORMAT ...] select_clause。它默认导出的文件的格式是原始格式(即字段之间用SOH分割的那种格式),无论表的格式如何,可以使用ROW FORMAT DELIMITED ...进行规定。
EXPORT
EXPORT 需要和 IMPORT 配合使用,EXPORT 的语法为EXPORT TABLE tb_name TO path,EXPORT 只能导出到 HDFS 中。IMPORT/EXPORT 主要使用在数据迁移中,因为它在导出时同时会携带所有元数据。
怪东西
另外的几种导出数据的操作是,直接使用 HDFS 的命令导出数据文件,或使用hive -e命令,执行单行 SELECT 脚本并把输出流指向特定文件(这种方法会把表头带上)。这些操作显然不会是最佳实践。
在这里停了一两个星期,去深入学习了 MapReduce 的编程模式,又顺势去复习了 SQL,学习了之前没有了解过的 GROUP BY,JOIN 操作,还有窗口函数,聚集函数……现在回过头来看 Hive,能更清晰些了。下一步是学习各种 SELECT,然后对这里的各个子句进行更加丰富的,结合实际的示例。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!