MapReduce 的魔法——Shuffle
实际上,Shuffle这个术语也存在于Spark这样其他的分布式计算引擎中,所以这里说的Shuffle的概念应该更加广泛一些,我觉得可以说:汇聚不同节点的数据到特定节点就是Shuffle操作,这种操作通常发生在按KEY的折叠操作,以及join等情况。
来自 HDFS 或其他地方的输入数据被切割成多个切片,每个切片交由一个 Mapper 负责,每个 Mapper 都将原始的数据映射(map,但实质是 flatMap)成为键值对的形式,这些键值对会经历某种魔法的过程以分发给各个 Reducer,然后每个 Reducer 处理它收到的 KEY 以及与这些 KEY 相关(associated)的键值对,并得到最终结果,保存在 HDFS 或其他地方;Mapper 的输出数据分发给各个 Reducer,这整个魔法的过程就是所谓的 Shuffle,今天对它进行一些了解,串联一下之前所学习到的东西。
Shuffle 分为 Mapper 端和 Reducer 端,称为 Map Shuffle 和 Reduce Shuffle。Shuffle 阶段解决的问题就是,如何尽量高效地将各个 Mapper 的输出传递给各个 Reducer,同时最大化减少 IO 和网络损耗,以及方便 reduce 方法的执行。
Map Shuffle
我经常把一个 map task 说成一个 Mapper,这在当前的大部分时候没有引起过歧义。
一个切片对应一个 Mapper,Mapper 会处理切片中的所有 KV 对形式的原始数据并映射成为输出的 KV 对,而 Map Shuffle 则是对输出的 KV 对进行处理,使其 partition,sort,combine,保存在本地硬盘中的过程。
切片是 MR 的抽象,它和 HDFS 的 block 默认是一对一的关系,但若是使用某种压缩小文件的 InputFormat,可能会成为一对多的关系;如果减少切片的大小,则可能是多对一的关系。
用户定义的 map 函数开始进行输出(context.write)时,输出数据并非被直接写入到硬盘中(我们知道,之后这些数据还得 partition,sort,combine,如果直接放到硬盘里,就得增加两倍时间的硬盘 IO 了)。出于效率,它会将结果缓存在一个缓冲区中以备处理。
其实 partition 在 KV 对给到环形缓冲区之前就计算出来了,见
MapOutputBuffer#collect的签名能够看到,分区号是作为参数传递进来的,而非是自己获取的。
每个 mapper 都有一个默认 100M 的环形缓冲区,输出的 KV 会进入该缓冲区;一旦缓冲区被使用超过 80%(默认值),则启动一个后台的线程把数据溢写(spill)到本地的硬盘,溢写的过程中 mapper 继续写数据,若填满则阻塞直到溢写完成,mapper 继续向缓冲区中写数据,如此反复。溢写完成后,硬盘中的结果文件将被合并成一个文件用来传递给各个 reducer。
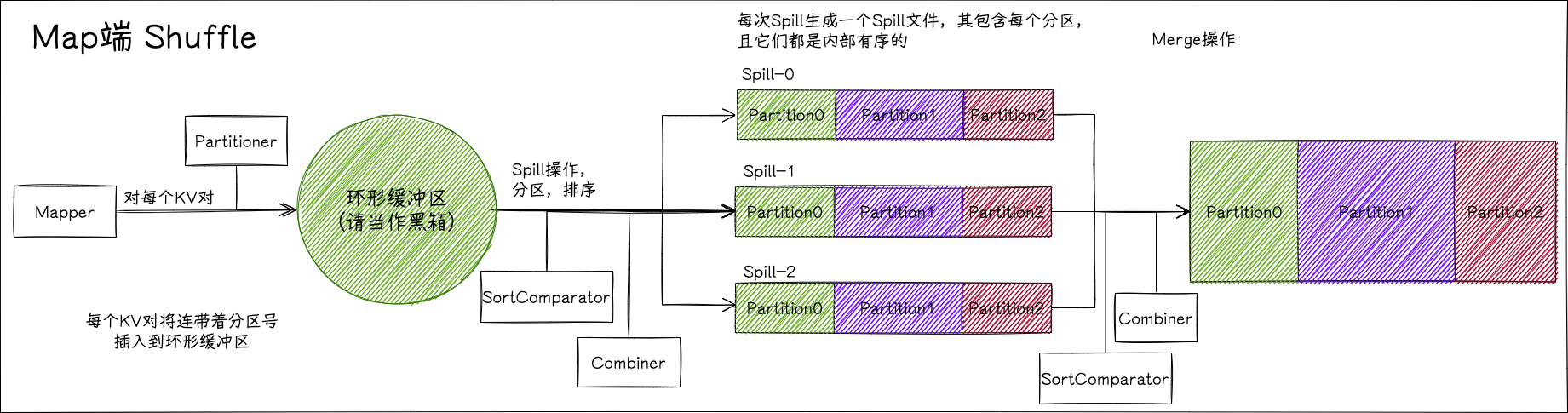
环形缓冲区和溢写是 map shuffle 的关键部分,了解了这两个部分,就了解了 map shuffle。
环形缓冲区
关于环形缓冲区的逻辑主要在org.apache.hadoop.mapred.MapTask.MapOutputBuffer#collect,但它状态太多,研究起来是非常麻烦的(不如说把我看麻了,几百行底层代码,还有同步操作),就目前来说,把它当作一个黑箱来看就好,具体的学习等之后背八股文的时候再说吧。
Spill(溢写)
溢写的过程并非是把数据直接写到硬盘中了事,为了减少硬盘 IO,它要在这里完成上面所说的 partition,sort,combine 操作,总的来说其过程如下——
- 每个 KV 对按分区号进行分区,分区号在 KV 对传递给环形缓冲区之前由 Partitioner 计算得出。
- 每个分区内的 KV 对按 KEY 进行排序(使用 SortComparator),传递给 Combiner(如果有的话)。
- 将溢写文件写到磁盘中,每次溢写都会产生一个溢写文件,每个溢写文件都包含每个分区的 KV 对,不同分区的数据能够被区分。(也就是说,达到 80% 这个阈值多少次,就会溢写多少次,出现多少个溢写文件)
有趣的是,在源代码里,调用的方法其实叫 sortAndSpill,是先排序再溢写,所以这里只取 Spill 其实不太合适。
merge
所有溢写文件都创建完成,即 Mapper 的所有原始数据都进行过映射且执行过上面的操作并写到硬盘后,要将所有溢写文件合并到一个文件中,其中每个溢写文件的同一个分区要进行归并排序(仍旧使用 SortComparator)以及进行 combine 操作,直到所有操作完成,这时候该单独文件包含所有分区的所有数据,且每个分区内部有序。
map 端的 shuffle 到此为止,它的最终目的是将 map 函数的输出键值对进行分区,排序并写到硬盘中成为一个单独的文件,其中,为了让 map 函数的执行和溢写操作能够(部分)并行以及更多优化,使用环形缓冲区来进行此操作。环形缓冲区之后还要继续研究。
Reduce Shuffle
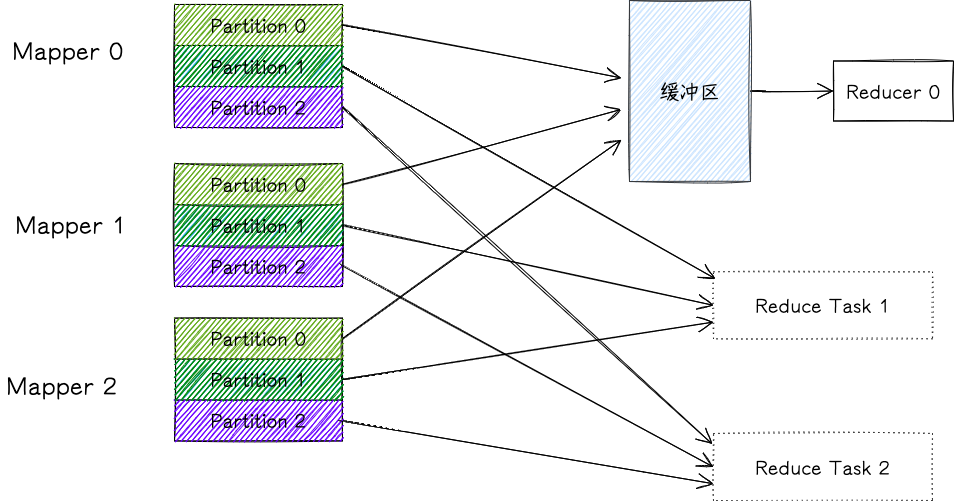
每个 Mapper shuffle 的结果都保存在其节点的本地硬盘中,Reducer 会从每个 Mapper 中拉取对应自己的 Partition(之前说的都是推,但实际上这里是拉),从每个 Mapper 中拉取 Partition 并进行归并就是 Reduce Shuffle 的任务。
当 Mapper 任务完成后,它会提醒 ApplicationMaster,然后 reducer 就能够从该 Mapper 处拷贝 Partition;拷贝 Mapper 的数据这个过程可以是并行的,即同时从多个 Mapper 处拷贝数据(默认并行数为 5),且该过程不需要待所有 Mapper 都完成后才进行。
reducer 像 mapper 一样,也会试图在内存中维护一个缓冲区,该缓冲区默认设置占内存的 70%,多余的数据将被溢写到硬盘中。从 mapper 处拿到的数据如果能够被放到缓冲区中则放置,否则放置到硬盘中;一旦缓冲区到达指定大小或接收到的 mapper 输出数量到达指定值,则会将其合并并溢写到硬盘中,其中可能会调用 Combiner(这里也会调用 Combiner!)以减少数量。
待所有 mapper 的输出均已保存在磁盘中(如果全部输出占的足够小,可能会一直在内存中进行维护,不持久化),则开始进行所谓的排序阶段,该阶段仍旧是合并操作,其将对所有 mapper 的输出进行归并,默认归并因子是 10,也就是说 10 路归并,最后一趟归并会直接传给 reduce 方法。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!