关于 Zookeeper 的一些笔记
一些(真的是一些) zookeeper 的 java 客户端的代码见此。最近在实际项目中也感觉到了能够使用 Zookeeper 的地方…显然,如果没有遇到过需要在分布式情况下进行同步的需求,就无法理解 Zookeeper “协调服务”的意义。
Zookeeper 这个名词听到过无数遍了,服务发现、集群配置、负载均衡有它,分布式锁有它,大数据里也有它,可是 Zookeeper 究竟是个啥东西?
是啥
Zookeeper 是一个开源的,分布式的,为分布式框架提供协调服务的中间件。Zookeeper 基于发布-订阅模式——它会存储和管理一些重要数据,并允许特定对象对这些数据进行订阅,若这些数据的状态改变则向所有对该状态进行观测的对象发起通知。Zookeeper 使用自己的一个虚拟的文件系统来存储数据,可以认为——
Zookeeper = 文件系统 + 监听/通知机制
尚硅谷的人说这是观察者模式,但普通的观察者模式中,消息的发布者是需要维护消息接受者的集合的,因此仍旧是一种松散的耦合,而 Zookeeper 应当是无耦合的——发布者(修改数据者)不知道有谁监听该数据,而接收者不知道是谁修改的该数据。因此我认为这是一个发布-订阅模式,其中发布者和接收者中间存在一个代理人 Broker,它就是 Zookeeper。
一些特点——
- Zookeeper 是主从架构,其集群由一个 Leader 和多个 Follower 组成(但 Leader 是可变的,不会有单点故障)
- 集群中只要有半数以上(不包括半数,所以奇数的节点是比较好的)的节点还存活,则 Zookeeper 集群就能正常工作
- Zookeeper 是 CP 原则,全局数据一致
- 同一个 Client 的请求按发送顺序执行
- 数据更新是原子的(和 Redis 一样)
- 集群节点之间数据同步实时性高
存储结构
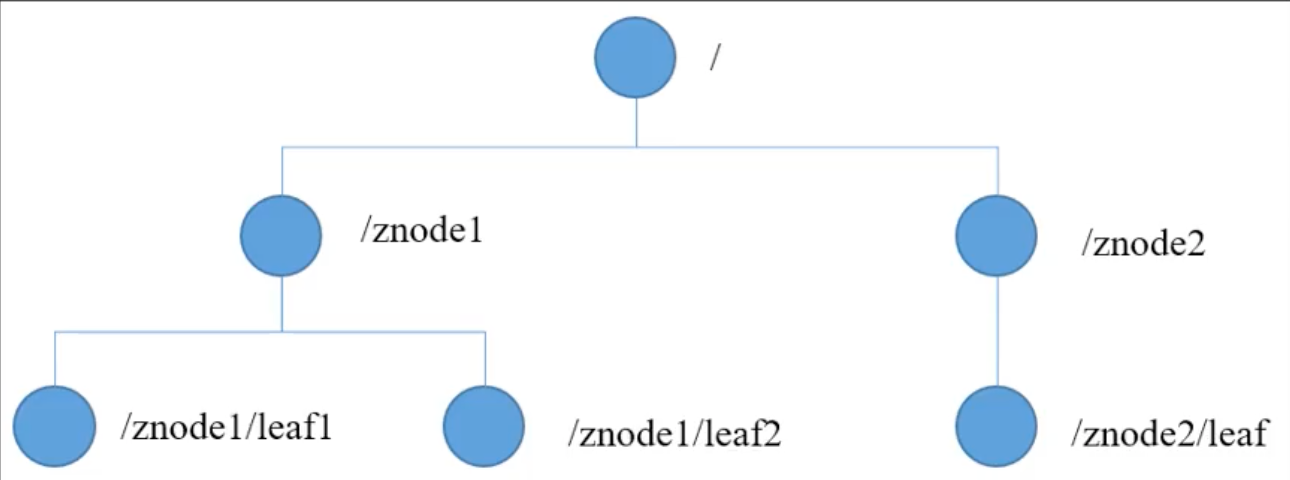
Zookeeper 的存储结构和 Unix 的文件系统类似,为树状结构,但不区分目录和文件,即不区分根节点和叶子节点,每个节点都称作 ZNode,默认存储 1M 数据,ZNode 通过路径唯一标识。
生产环境下的部署
并非集群中的每台机器都需要部署 zk 节点——
- 10 台服务器:3 个 zk
- 20 台服务器:5 个 zk
- 100 台服务器:11 台 zk
- 200 台服务器:11 台 zk
客户端监听
客户端监听的事件分为两类:节点数据的变化;子节点的数量增减。
监听是一次性的,一旦监听到了事件,触发后监听就被取消了。
写操作
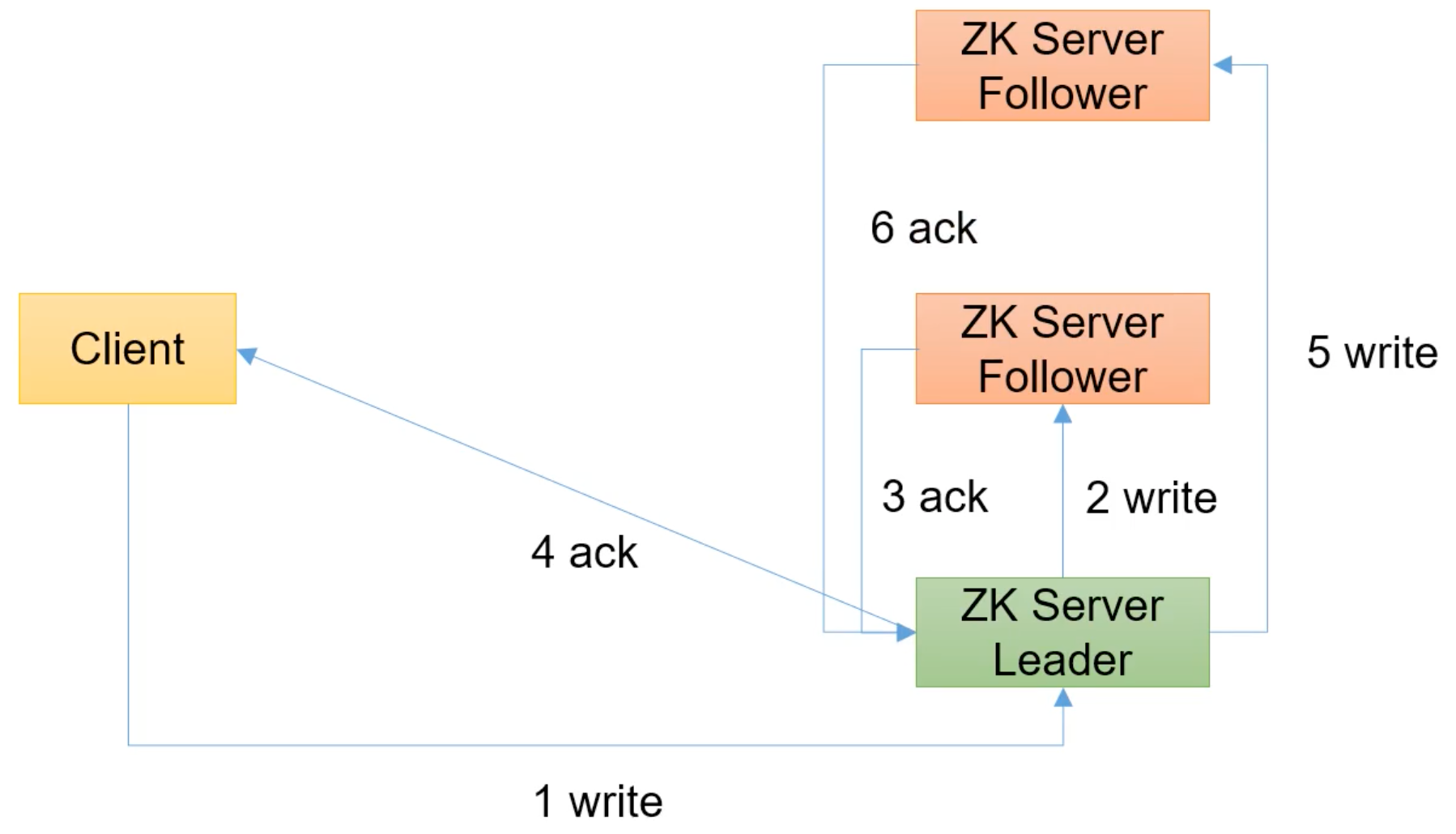
写操作发送给 Leader 的情况,Leader 有写权限,直接写自己,然后向 Follower 发起写请求,等待 ACK,当写的节点超过半数,则认为写成功,向客户端发送 ACK;发送后再继续向其他 Follower 发送写请求,等待 ACK,直到所有节点都写入。
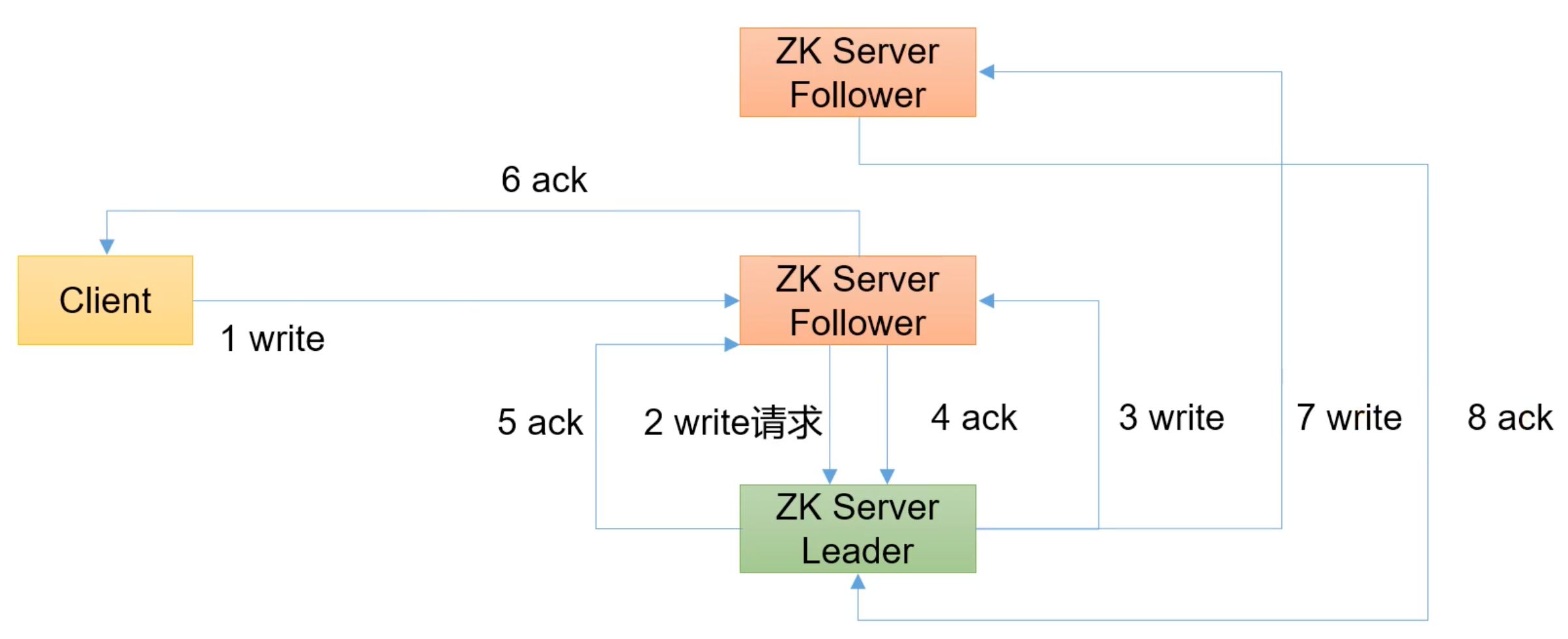
写操作发送给 Follower 的话,Follower 直接把操作转发给 Leader,让 Leader 进行处理;Leader 自己先写,然后向该 Follower 发起写请求,等待 ACK;超过半数后,Leader 向该 Follower 发起 ACK,该 Follower 再把 ACK 发送给客户端(注意 ACK 的发送者必定是客户端请求的接受者);之后操作同上面一致。
猜测两个客户端同时对同一个节点进行写操作(比如分布式锁),必有一个失败,因为两个操作必须得到半数以上的节点都进行过写操作,这其中必然会出现版本号,ID 之类的冲突,这里总共有三种情况——两个操作都打到 Follower 上;两个操作都打到 Leader 上;两个操作分别打到 Follower,感觉三种情况都能在 Leader 处得到妥善处理。
关于选举
第一次选举即服务器启动时,ID 最大的胜出;其后的选举(每一个节点新加进来都会发起选举,每一个节点的网络出现问题,使它以为 Leader 不存在时,会发起选举)中,按如下的规则选举——
每个节点有三个属性——选举轮次 EPOCH(选举了多少次,有的节点可能会“火星”,都不知道有发生过选举),事务 ID(每次进行修改都会增加事务 ID),服务器 ID(即 myid)。
- 如果某节点选举轮次最大,则它获胜
- 选举轮次相同的,事务 ID 最大的获胜
- 事务 ID 相同的,myid 最大的获胜
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!