Hello, MapReduce——Word Count
感谢 Docker,对各种环境的反复试验和修改从而变得可行,折磨了三四天后,我总算弄出了一个好用的 docker…集群,它足够易自定义以方便我快速搭建 hadoop 的环境,让我能专心“业务”,从这些玩意上解放出来。

总之,在之前了解了 Hadoop 的 HDFS,学习了它的原理,终端的一些操作以及 JavaAPI(每个方法都受检,不愧是你!),现在到了真正解决问题的时候了——MapReduce。这里做下关于 MapReduce,以及它的第一课——WordCount 的笔记,主要参考 Hadoop 权威指南以及尚硅谷的视频(官方文档未免跳的太快)。
MapReduce 是什么
MapReduce 是一个基于 Hadoop 平台的,高度并行的分布式运算框架(与此相对地,HDFS 是系统),它能充分利用多核处理器,并具有高度的容错性,能够处理海量的数据。用户只需继承简单的抽象类便可轻易嵌入自己的业务逻辑并交付给服务器(实际上是 Yarn,ResourceManager)执行。同时借助 Hadoop Stream,它可以使用其他语言对 Mapper,Reducer 进行编写。
MapReduce 的优点如下——
- 容易编程,对用户来说,他只需要关心 Map 和 Reduce 的业务逻辑即可,关于任务的调度和分配,各节点的通信等细节都是透明的(必须表扬这点:它对此做了足够的抽象,以至于相关代码在本地执行还是在远程的 HDFS 上执行对用户来说都是一样的,因此对其进行调试非常容易——在本地执行即可)
- 容易横向扩展
- 高容错性,即使特定节点的任务失败了,它仍旧能自动地将该任务分配给其它节点,不会导致整个任务直接挂掉
- 支持海量数据(TB 级,PB 级)的计算
缺点如下——
- 无法支持实时计算
- 不擅长流式计算——使用的数据必须预先准备,无法后续再添加;Spark 擅长此项
- 不擅长迭代式计算——后面的计算需要使用前面计算的结果的计算;Spark 擅长此项
- 关于 MapReduce 为什么叫 MapReduce,我认为这是因为它的执行过程典型地出现了 Map 和 Reduce 操作——
它首先会将任务划分成互相独立的多个部分,交与各节点去执行,得到一个输出,如果将任务的各部分看作一个集合,这就成为了一个典型的 Map 操作——对集合的每一个元素执行相同的操作,得到对应的结果并组成新的集合。划分任务由框架负责,而各节点执行的 Map 操作称为 MapTask,大小为块大小。
但有一说一,MapTask执行的操作更像是
flatMap,每一次执行Map操作时都能够向上下文中写入复数的数据,这些数据最终是扁平的。
将各节点的输出结果进行汇总得到最终结果是算法的第二部分。如果将各 MapTask 的结果当成一个集合,则这就成为了一个典型的 Reduce 操作——将集合中每一个元素“积累”到一个值上,而每一个 Reducer 的行为实际上也是 reduce——将 Mapper 的中间结果中的“一类值”累积到一个值中;各节点要进行的 Reduce 操作称为 ReduceTask。
当然,问题远没有这么简单,比如这里想当然可以提一个问题——Reduce 操作怎么并行?答案应该可以概括为——每个 ReduceTask 处理“同一类”数据。显然我们不能单单从函数式编程的角度来对 MapReduce 望文生义——在 MapReduce 的实际架构中,还得引入几个额外角色——Combiner,Partitioner;在 Map 和 Reduce 阶段中间,有着所谓的 shuffle 阶段;MapReduce 强迫数据必须使用 KV 对的形式……想必这些都是为了能最好地并行化。
一个需要特别注意的地方是,MapReduce 的输入,输出以及所有中间结果必须保存在硬盘上(但不一定保存在 HDFS 里,如 Map 的中间结果是不会落到 HDFS,而是落到本地文件系统中),这会增加许多 IO 时间,实际上让 Hadoop 难以处理实时计算任务。
不一定!如果自定义 OutputFormat,输出可以不是 HDFS,它可以是数据库,本地硬盘,或第三方系统!
题外话——关于并行的 reduce,我想到了 java8 stream 里的 reduce,它和 Java8-reduce 都为并行情况做了特殊处理,并且它们中都有个叫”Combiner”的角色,虽然其在两者中发挥的作用是不同的。
WordCount 一窥
先从一个实例来看一看怎么编写 MapReduce 的业务代码,这里选择官方推荐的教程案例——wordCount,统计字符串中各单词的数量。
WordCount 程序可以这样描述——
- 先将输入字符串按行切分成许多个 MapTask,分配给各节点处理
- 各节点将 MapTask 中的字符串每行按字符串划分,统计每行每个单词的出现,将结果输出
- MapTask 的结果在本地预先进行一次聚集,经框架汇总和处理后被按特定顺序进行排序、分组、将每个组传递给特定的 ReduceTask,分配给各 Reducer 节点处理(MapTask 的数量和数据集的大小成正比,而 ReduceTask 的数量是独立指定的)
- 各节点统计各单词出现次数,输出结果到文件中
- 框架汇总输出文件,得到最终输出文件
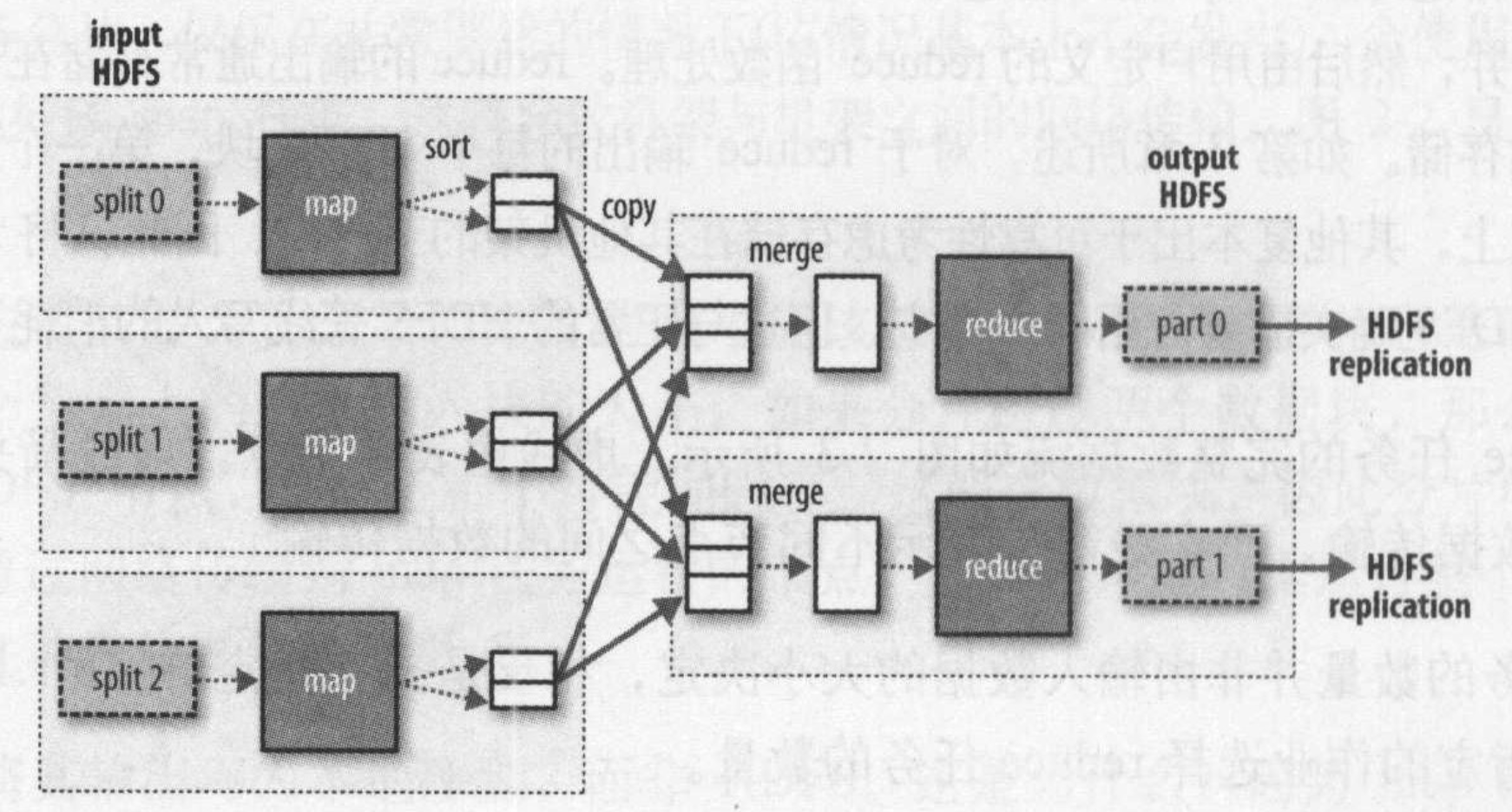
每个 ReduceTask 都包含所有 MapTask 的结果的一部分,比如说,假设它的 partitioner 是按字符串的“基数”进行分区,则 MapTask1,2,3 的结果中可能所有 A、B、C 开头的所有单词会传递给 ReduceTask1,D、E、F 开头的所有单词会传递给 ReduceTask2……但实际的 partitioner 一般使用哈希算法,以保证分区尽量均匀;而用户则需要保证每个 MapTask 的输出值尽量均匀,即每个 K 对应的 V 的数量尽量相同,从而保证每个 ReduceTask 的工作量基本相同。
另外,也是由于每个 ReduceTask 都需要拿到所有 MapTask 的结果的一部分,ReduceTask 因此享受不到数据本地化的优势——MapTask 的结果必须通过网络传输给 ReduceTask。
MapReduce 程序中,用户最少需要编写三个部分——Driver:程序的入口,创建配置和 job;Mapper:处理 MapTask 的业务类;Reducer:处理 ReduceTask 的业务类。
Mapper 和 Reducer 使用和产生的数据都为 KV 对的形式,Mapper 的接口形如Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>,其中 KEYIN 为输入数据的标识符,VALUEIN 为输入数据,KEYOUT 结果数据的标识符,VALUEOUT 为结果数据,Mapper 中的 map 方法为我们需要重写的业务方法,它的签名为void map(KEYIN, VALUEIN, Context)(Context 为实现 MapperContext 的类,它包含了所有所需类型信息),map 方法对每一个输入数据的 KV 对都会调用一次,Context 负责对应输出文件等信息,看签名就知道,这方法的结果必须要通过 Context 写出去。
在 WordCount 实例中,KEYIN 是行的偏移量(不是行号,是该行相对于文件开头偏移多少字节),VALUEIN 是该行的内容。WordCount 的 Mapper 大概长这样——
1 | |
Mapper 的 map 方法是典型的推模式——服务端,即任务的上下文,一行一行地把数据推给 mapper 的 map 方法,期待其做出动作,该操作就像处理 STDIN,消息队列的接受者,MVC 框架中的控制器……
而拉模式,则是把所需的数据直接拿到而进行处理,倘若重写 run 方法,就能得到所谓的拉模式了,也可以将每一行数据都暂存在成员变量中,在 cleanup 方法时一次性全处理掉,这似乎也可以称作一种拉模式?
Reducer 接口的签名为Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>,它的输入的类型必须和 Mapper 的输出的类型一致。Reducer 的接口和 Mapper 的形状一样,但是它的行为和 Mapper 不同:Reducer 的业务方法 reduce 对“每一类”的对象,即 KEY 相同的所有 KV 对数据执行一次,这可以从 reduce 的方法签名中一窥——void reduce(KEYIN, Iterable<VALUEIN>, Context)。显然,框架必须在内部做一些分组的活。
Reducer 的示例大概长这样——
1 | |
Hadoop 的官方示例把用到的 Text 和 IntWritable 都作为成员变量了,这虽然性能会好一些(真的会好吗?在现在的 jvm 这样变态的优化下?),但是严重影响了代码的可理解性(任何有编码经验的人都知道把可变对象的引用传给别人后再对它进行修改绝不是好主意)。
为了强迫自己接受这种写法,这里必须记住一个前提——context.write方法接收到输入后会立刻进行某种复制(或持久化),因此它引用的数据,即 Text 和 IntWritable 即使修改了也不会产生任何影响。这个前提在细节上出现错误也不要紧,的确是这个效果就好。
Driver 的示例平平无奇,这里是使用本地文件系统的情况。很棒的一点是,无论是直接跑还是打成 jar 包发到 hadoop 集群里跑,它的代码(甚至配置)是不需要做任何改动的。
1 | |
示例代码见此。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!