《两周自制脚本语言》笔记 4——Stone 语法的设计
Stone 语法的设计
借助 BNF,现在对 Stone 语言进行设计。首先确认程序中的终结符——程序终究要“收敛”到终结符的集合——NUMBER,IDENTIFIER,STRING,OP,EOL,其分别代表整型字面量、标识符、字符串字面量、双目运算符、换行符。
显然,双目运算符应当从标识符中分化出来……或是说修改 Token?
1 | |
- primary:最基本的“值”。
- factor:这里的目的是引入负数操作符。
- expr:表达式——程序最基本的表达部分。
- block:代码块。
- simple:expr 的别名。
- statement:所谓的语句,这里只实现了 if,while,以及表达式(我们知道,表达式也是语句,可以独立地作为一行出现,虽然其没有任何意义)。
- program:单个语句。
该书作者编写了通过 Java 代码生成语法分析器的库,这里先不究其细节(在将来再去研究!),直接去研究,statement 生成如何的 AST,如何去求值。
生成 AST
语句所生成的 AST 非常类似,下面展示了一些语句的 AST。
1 | |
为了生成 AST,需要对每一种可能的语句进行定义——其最终都会作为 AST 中一个子树存在。这段代码出现了如下语句定义——
- IfStatement:其子树包含 Condition 表达式,thenCondition 语句块,elseCondition 语句块(可选)。
- BlockStatement:语句块,其子树包含任意数量的语句。
- BinaryExpr:其子树包含 Left 表达式,Op 运算符,Right 表达式。
- 以及一些“值”,这里不表。
考虑到这些语句所拥有的子树数量是不一致,甚至是不确定的,因此不能采用固定的树形结构。这里为图简易,使用 List 来保存子树,并给定访问特定子树(子语句)的方法。
Parser 原理
作者编写的库提供了一切这里所需的方法,使能够生成正确的子树,这其中包括获取正确的根结点,以及生成正确的子树的集合。比如,通过其表述的 block 的 parser 如下——
1 | |
每一个 Parser 都拥有两个成员——AST 工厂和 Element 数组,其中,Element 数组为保存所有匹配模式的集合——所有模式!它要保存用于进行语法分析的一切模式,除 rule 外任何方法都将“充实”这个集合,比如下面列出了读取非终结符和读取分隔符的方法,其中 Skip 和 Tree 都是 Element。
1 | |
一切 Element 都负责进行特定的模式匹配——Skip 将匹配并丢弃特定的标识符,Tree 将持有一个 Parser,用来匹配非终结符……这样的 Element 的序列就能够负责特定 Parser 的解析工作。
AST 工厂为利用 Element 序列构造 AST 节点的类。其主要操作是统一的——根据 Class 动态构造工厂;获取构造函数;通过特定输入参数和构造函数构造 AST 节点。需要这样实现的原因是进行抽象——不同 AST 节点的构造函数可能是不同的,这就意味着其不能通过接口来对节点的创建方法进行约束(如果硬要这么干,那这方法的输入参数得是 Object,而这是非常不好的)。
为什么要这么干?我的第一想法是无论是语句还是原子,全都使用同一种输入,即 AST 节点序列,原子使用特定标识,其有且仅有一个子树。这样似乎是合法的……就像 haskell 那样,一切皆函数,只不过这个函数不接受参数,返回常值而已。并且这样生成的 AST 在之后还能被优化成和使用书上方法所生成 AST 一致。
下面展示了生成 AST 工厂的静态方法——rule 方法将会间接调用该方法。如果传入 class,将生成构造该类型 AST 节点的工厂;如果不传入 Class,则 clazz 为 null,因此 get 方法返回 null,最后生成的 AST 子树的根节点将没有特定类型。
怀疑这里的描述可能会有错误。等之后手写语法分析器的时候再思考吧!
1 | |
可见,其如果其只有一个子树,则其将忽略该根结点,直接返回其子树(许多 Parser 都依赖这一行为来减少树深度!);如果有多个子树,则原样返回——也就是说最后构造的子树的根结点是原始的 ASTList 实例。
下面展示了x + -y的 AST,这书又犯了错误——左右写反了。
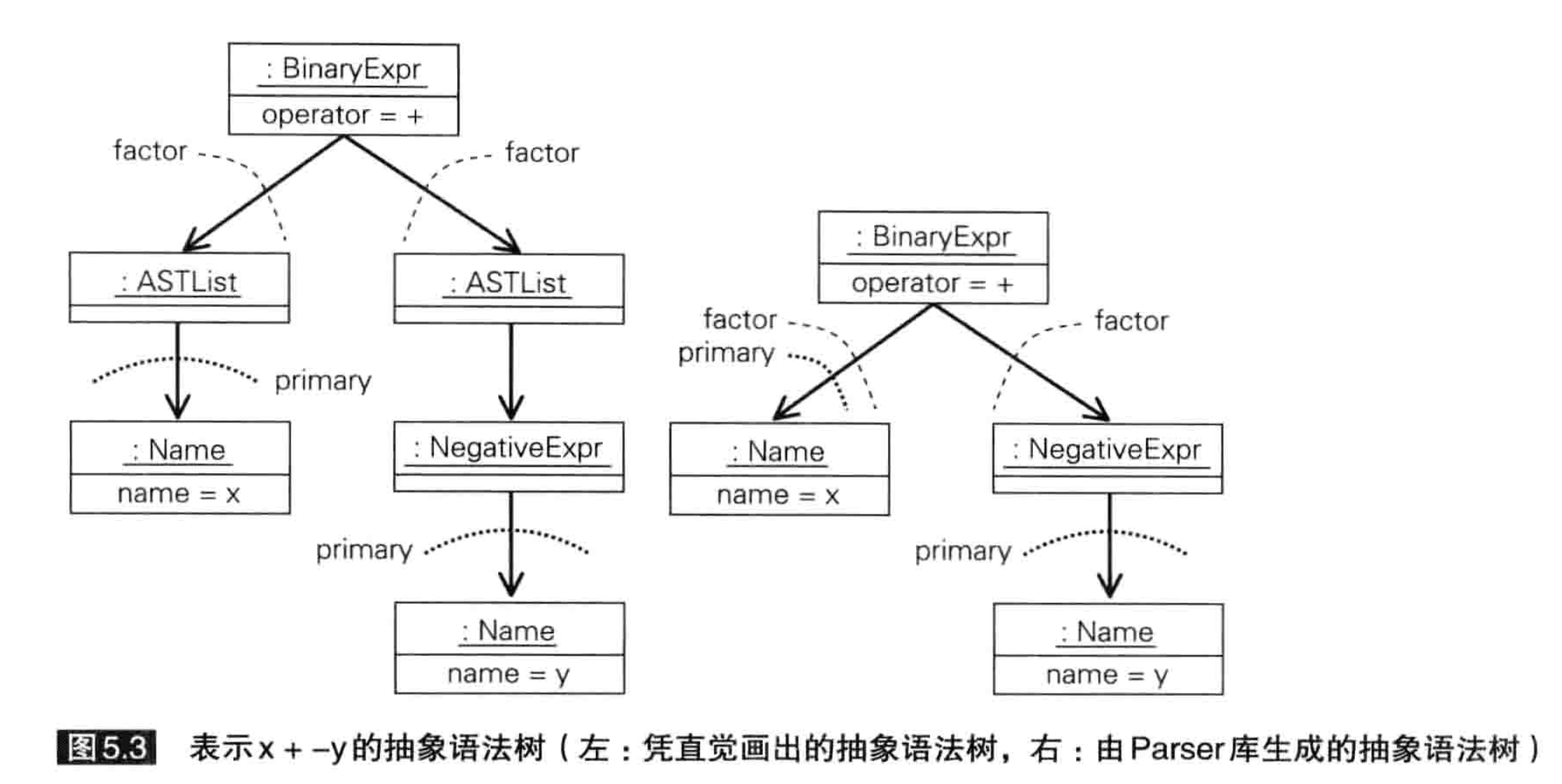
再比如,下面图片(根结点应当为 ASTList!这书为什么总是犯错误?)中,对应的 BNF 为adder: NUMBER "+" NUMBER,其根结点没有任何多余信息(这让我想起 Lisp 的 quote)。
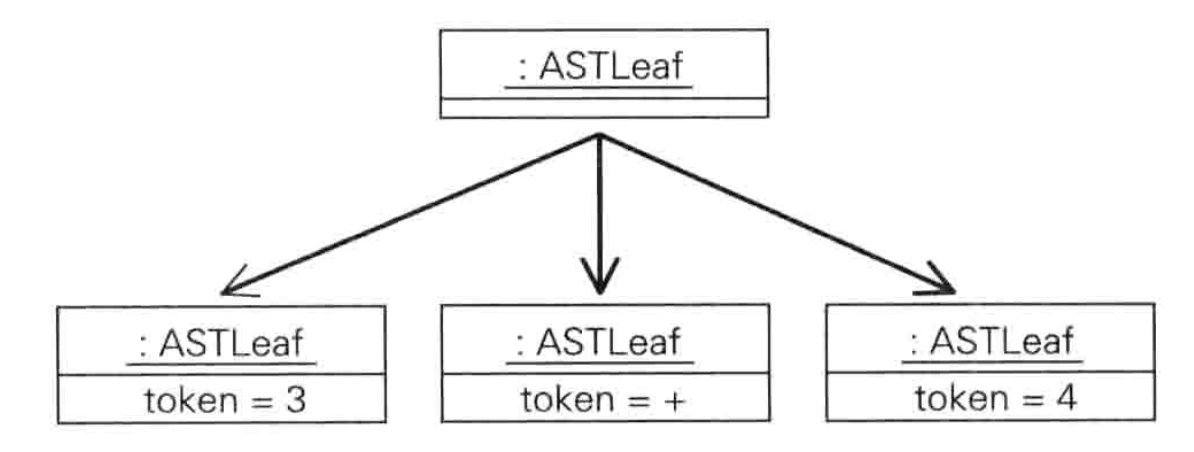
该框架在进行表达式识别的时候能够方便地规定运算符的优先级以及结合性(左结合,右结合),它使用的是算符优先分析法(之前有提到过),这也是之后需要去了解下的。
这里对 Stone 的语法以及进行了一些描述,接下来是 AST 的解释执行——实际上就是根据各个子树的根结点的类型,编写相应 eval 方法并递归执行直到得到结果。其中,有的将利用其副作用——输出,变量/函数定义、赋值等,有的则将利用其返回值。副作用是一个语言所必须的东西——否则它不会对外界造成任何影响,自然也不会有任何意义。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!