LangChain 学习 02——工作流,Chatbot
通过看 LangChain 关于 Chatbot 的教程,peek 一下 LangGraph,以及做一个带会话记忆功能的 AI。
学习全新东西的时候,笔记也会做得一地鸡毛,这是挺正常的事情,不是吗?
为何 LangChain 把记忆功能挪到 LangGraph?
原来的记忆功能其实仍旧存在,但原因应该是,之前的实现不够通用且功能不够强大,而且似乎是和 Runnable 耦合的,开发者可能不太喜欢这种设计。他们重新在 LangGraph 中实现了更强大的记忆功能,包括时间旅行,提高通用性(支持任意自定义状态,工具调用记录……)。
LangGraph 环境搭建
其实似乎不该在这里的时候就直接跳到 LangGraph……?LangChain 的 Chain 还没学到呢!
首先是关于 LangGraph 的环境搭建:
1 | |
简单复习
这里也当作复习了——还记得 LangChain 是怎么用的吗?我记得 LangChain 提供了模型(继承自 Runnable)和消息的抽象,提供了 Document Loader,Embedding,Splitter,VectorStore,Retriever 这些抽象(只要记住 RAG 的流程,这个还挺容易回想的)。
但是,还记得怎么加载模型和直接使用它吗?(查看 import 列表的时候猛然意识到 langchain 的东西其实很少,我甚至有可能把所有东西都过一遍)
1 | |
'好的,再来一个程序员笑话: \n\n **程序员去超市买菜** \n 老婆打电话:“下班买五个包子,如果看到卖西瓜的,买一个。” \n 结果程序员带回来一个包子。 \n 老婆问:“怎么只买一个?” \n 程序员:“因为我看到卖西瓜的了。” \n\n(逻辑没毛病,但今晚可能要跪键盘了😂)'
很好。向量数据库那边的东西我就不再重新回忆了……等下面实际学 RAG 的时候再说。
回到正题,关于 LangGraph。
初探工作流
首先有如下出发点:
- LangGraph 定义一个图,或者说工作流;大模型(在实操中是工具函数?),是这个图的节点
- 图有全局状态,每个节点都能访问这个全局状态
- 工作流对节点内容不知晓,甚至不知道里面究竟有没有大模型
直接拷贝官方样例代码:
1 | |
注意到这里出现诸多新术语,State,MessagesState,StateGraph,Node,Worlflow,Checkpointer,MemorySaver,CompiledGraph。注意这里的 call_model 函数接受 state,但同时又返回 state(检查文档,是State -> Partial<State>,这帮家伙原本写 ts 的?)。
注意到 LangGraph 提供了一个虚拟节点 START,这样就不需要提供一个set_start的方法了,直接使用 add_edge 去添加实际的头结点,非常聪明!但其实仍旧有相关方法 hhh。
但文档中没进一步解释这各部分是干嘛的,那我就把各部分跟着代码文档先 peek 一下再跟着它的步调来。
- State:指代的就是任意的状态,并不存在 State 这个抽象
- MessagesState:本质上是一个 TypedDict,只有一个字段 messages 存储会话历史;注意 MessagesState 本身是被工作流知晓的,而且工作流把它当成一个 Schema,这证明在工作流内部会有不止一个 MessagesState,实际上正是如此——对每一个会话(thread)(的每一个快照(checkpoint)?),肯定都会有一个自己的 MessagesState。
- StateGraph:有状态的图,所有节点之间通过共享状态去进行交互。状态的内容比这里写的还更复杂,能提供一个 reducer 之类的,后面再表;注意这个图的定义非常松散——先添加了到 model 的边,再添加 model 到图里,估计图定义错了只有在运行时或者 compile 时报错
- Checkpointer:应该是提供保存快照的功能。
从字面意思上理解,上面定义了一个工作流,这个工作流实际上是一个有状态的图,但有趣的是,这个工作流实际上对大模型并不知晓,它只知道有个函数可以调,但不知道这个函数内部是什么魑魅魍魉。然后,这个工作流进行 compile,这个 compile 应该是检查和“实例化”图的“定义”,并将其编译成一个图的“实例”供后面使用,然后同时进行依赖注入,得到实际供使用的 app。
这里的图的“实例”命名为 app,显然它就是我们主要要使用的部分。我们来进行一些测试,先不考虑大模型:
1 | |
{'counter': 1}
{'counter': 101}
{'counter': 102}
'---下面的是有状态的---'
{'counter': 1}
{'counter': 2}
{'counter': 101}
{'counter': 102}
{'counter': 1}
{'counter': 201}
好吧,注意到一点——图本身实际上是无状态的……把这个图称为 StateGraph,文档说是所有节点都共享状态,这个说法其实和实际行为是不搭的,并非如此——我们可以认为所有节点都是纯的(虽然不是那么纯……),因此整个图也是纯的。
实际上没有所谓的共享状态——用户输入一个状态,这个状态在不同节点之间流转并返回,仅此而已。
但又注意到,我们使用 checkpointer 时,看上去就有状态了——这是因为这个 checkpointer 在维护状态,并且状态通过一个 thread_id 去进行标识,我们每次调用图的 invoke 方法的时候,实际上是先从 checkpointer 中取状态,然后再从用户输入中取状态,用用户的输入和 checkpointer 中的状态进行合并(和覆盖)。
所以,图其实是很轻量的,它无状态,只是一个流程的有机的序列,每个节点都很轻松,甚至可以看成是纯函数(只要它不报错,哈哈哈)。大概是这么个感觉。
flowchart LR
用户输入 --> Checkpointer --> A["图(工作流)"] --> 输出
输出 --> Checkpointer
Chatbot
上面对着官方样例代码做了一些分析和测试,感觉自己已经部分地学懂弄通了(结果是自己“发现”的,很有乐趣)。
现在,我们回到官方的示例,带着已有的知识重新检查上面的工作流的节点定义:
1 | |
wait a minutes……我们知道,MessagesState 中,messages 字段是list[BaseMessage]啊?为什么这里 return 的是一个 BaseMessage?
这是因为,State 类允许配置一个 reducer——它允许节点返回的值和实际的状态不同,reducer 把这个值和原来的状态做合并,实际上这个行为就像函数式编程里的 reduce。我们可以自己重新实现 MessagesState:
1 | |
input state {'some_list': [234]}
{'some_list': [234, 123]}
input state {'some_list': [234, 123, 555]}
{'some_list': [234, 123, 555, 123]}
注意到——定义节点时,入参是 acc(原始状态),返回值是 x(状态增量);使用工作流时,入参始终是 x(状态增量),返回值是 acc(原始状态)。下面实际使用官方样例进行对话。
1 | |
{'messages': [HumanMessage(content='你好,我的名字是友纪', additional_kwargs={}, response_metadata={}, id='2fcddbb2-0152-4367-85cd-3456e2ad7d30'),
AIMessage(content='你好,友纪!很高兴认识你~(*´▽`*) \n 请问今天有什么想聊的,或者需要帮忙的事情吗?无论是分享心情、提问,还是随便聊聊,我都在这里哦!✨', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 48, 'prompt_tokens': 10, 'total_tokens': 58, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 10}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_3d5141a69a_prod0225', 'finish_reason': 'stop', 'logprobs': None}, id='run-c8258430-184c-4a25-8cd2-d32df0bcf56a-0', usage_metadata={'input_tokens': 10, 'output_tokens': 48, 'total_tokens': 58, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
{'messages': [HumanMessage(content='你好,我的名字是友纪', additional_kwargs={}, response_metadata={}, id='2fcddbb2-0152-4367-85cd-3456e2ad7d30'),
AIMessage(content='你好,友纪!很高兴认识你~(*´▽`*) \n 请问今天有什么想聊的,或者需要帮忙的事情吗?无论是分享心情、提问,还是随便聊聊,我都在这里哦!✨', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 48, 'prompt_tokens': 10, 'total_tokens': 58, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 10}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_3d5141a69a_prod0225', 'finish_reason': 'stop', 'logprobs': None}, id='run-c8258430-184c-4a25-8cd2-d32df0bcf56a-0', usage_metadata={'input_tokens': 10, 'output_tokens': 48, 'total_tokens': 58, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}),
HumanMessage(content='我的名字是什么?', additional_kwargs={}, response_metadata={}, id='6bbda2b7-c15f-45f8-9721-bac2d8bb44e9'),
AIMessage(content='你的名字是**友纪**呀~刚刚告诉过我的,我可没有忘记哦!(◕‿◕✿) \n 需要我用这个名字为你做点什么吗?比如: \n- 记录你的偏好(喜欢的颜色、食物等等) \n- 写一首藏头诗 \n- 或者…直接叫你“友纪酱”? 😄', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 75, 'prompt_tokens': 65, 'total_tokens': 140, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 65}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_3d5141a69a_prod0225', 'finish_reason': 'stop', 'logprobs': None}, id='run-48ee6d58-7171-4ccc-8e56-c05d5c90e412-0', usage_metadata={'input_tokens': 65, 'output_tokens': 75, 'total_tokens': 140, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
然后,如果要异步调用的话,就把 call_model 定义成 async 的,并使用图(Runnable)的ainvoke方法。
如何设置系统 prompt?
在这里会有一个问题——我如何设置系统 prompt?系统 prompt 要存储进状态吗?答案是不必要——我们另外存系统 prompt,每次调用的时候把系统 prompt 放到最开始:
1 | |
使用 promptTemplate 也是同样的思路:
1 | |
无论如何,系统 prompt 都不会被存进状态中。
对话历史管理
对于这种多轮对话的情况,一个很常见的需求就是对话历史管理——对话不能无限地拓展,不然 token 会用的越来越多,AI 的反应会越来越慢。通常有如下的需求:
- 系统指令仍旧需要出现
- 第一条 prompt 通常需要是人类的
- 需要限制总 token 数量,通常是取最近的对话作为窗口
LangChain 提供了一个 trim 会话历史的抽象(它仍旧是 Runnable):
1 | |
流式输出
这里就真的是魔法了…………………………它怎么做到的,它怎么做到的??
stream 的默认 stream_mode 配置下,输出的会是同一条消息在每个步骤(node)下的响应;这里我们要的是流式输出,所以我们配置stream_mode="messages",这会使得会进行 token-by-token 的输出,注意到每次迭代会返回两个值——AI 的输出,以及是哪个步骤、节点输出的,后者在多节点的工作流中有意义。
那么,工作流究竟是如何通知大模型要使用流式输出的?能够猜测,背后肯定有何全局变量或者线程局部变量被修改了,让大模型开始进行流式处理;而且 LangGraph 把这个操作封装的很好,我们无法进行观察。(这里的说法是错的,见下一篇笔记)
1 | |
content='' additional_kwargs={} response_metadata={} id='run-1d69bb9d-f58e-4765-a28f-73c96a9a7812'
{'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model', 'start:model'), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
---
content='你好' additional_kwargs={} response_metadata={} id='run-1d69bb9d-f58e-4765-a28f-73c96a9a7812'
{'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model', 'start:model'), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
---
content='!' additional_kwargs={} response_metadata={} id='run-1d69bb9d-f58e-4765-a28f-73c96a9a7812'
{'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model', 'start:model'), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
---
content='😊' additional_kwargs={} response_metadata={} id='run-1d69bb9d-f58e-4765-a28f-73c96a9a7812'
{'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model', 'start:model'), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
---
content=' ' additional_kwargs={} response_metadata={} id='run-1d69bb9d-f58e-4765-a28f-73c96a9a7812'
{'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model', 'start:model'), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'checkpoint_ns': 'model:f4a4c40f-ad74-c062-58df-99c93af1e3e2', 'ls_provider': 'openai', 'ls_model_name': 'deepseek-chat', 'ls_model_type': 'chat', 'ls_temperature': None}
---
上面完成了 Chatbot 教程,但能够注意到,上面虽然使用了工作流,但这个工作流只有一个节点,我们实际上只是利用了工作流的 checkpointer 功能。而下面的 RAG 和 Agent,才是见真章的时候。
Agent 一窥
要尝试建立对 Agent 的系统的认知,以及知晓如何使用 Agent 去实现 RAG,这里只是一窥它的强大,后面得继续深入学习,但要避免把内容搞的太长。
LLM 自己除了生成文本无法做任何事情,而 Agent 则利用 LLM 作为推理引擎,使得能够使用 LLM 去进行操作,或者说能够让 LLM 能够操作外界。
下面的代码直接创建了一个 ReAct 的 agent,并依赖 tavily 搜索引擎提供联网搜索能力——LangGraph 直接提供了这个,prebuilt!牛逼。
1 | |
================================[1m Human Message [0m=================================
现在武汉天气如何?
==================================[1m Ai Message [0m==================================
Tool Calls:
tavily_search_results_json (call_0_132935db-b027-4038-ab81-3aa7e6511625)
Call ID: call_0_132935db-b027-4038-ab81-3aa7e6511625
Args:
query: 武汉天气
=================================[1m Tool Message [0m=================================
Name: tavily_search_results_json
[{"title": "武汉 - 中国气象局-天气预报-城市预报", "url": "https://weather.cma.cn/web/weather/57494.html", "content": "主站首页、n 领导主站、n 部门概况、n 新闻资讯、n 信息公开、n 服务办事、n 天气预报、n 首页、n 天气实况、n 气象公报、n 气象预警、n 城市预报、n 天气资讯、n 气象专题、n 气象科普、n 首页 国内 湖北 武汉、n 国内 \n|\n 湖北 \n|\n 武汉 \n 更新、n \n \n7 天天气预报(2025/02/10 12:00 发布)\n 星期一、n02/10\n 晴、n 无持续风向、n 微风、n13℃\n0℃\n 多云、n 无持续风向、n 微风、n 星期二、n02/11\n 小雨、n 西南风、n 微风、n10℃\n6℃\n 小雨、n 西北风、n 微风、n 星期三、n02/12\n 小雨、n 北风、n 微风、n8℃\n2℃\n 晴、n 北风、n 微风、n 星期四、n02/13\n 阴、n 西南风、n 微风、n10℃\n2℃\n 小雨、n 东风、n 微风、n 星期五、n02/14\n 小雨、n 西北风、n 微风、n6℃\n4℃\n 小雨、n 西南风、n 微风、n 星期六、n02/15\n 晴、n 西南风、n 微风、n15℃\n0℃\n 多云、n 东风、n 微风、n 星期日、n02/16\n 晴、n 东北风、n 微风、n17℃\n0℃\n 晴、n 东风、n 微风、n 时间 17:00 20:00 23:00 02:00 05:00 08:00 11:00 14:00\n 天气 [...] 气温 9.1℃ 2.6℃ 南风 2 级", "score": 0.79732054}]
==================================[1m Ai Message [0m==================================
根据最新的天气预报:
- **今天(02/10)**:晴,气温在 0℃到 13℃之间,无持续风向,微风。
- **明天(02/11)**:小雨,气温在 6℃到 10℃之间,西南风转西北风,微风。
- **后天(02/12)**:小雨转晴,气温在 2℃到 8℃之间,北风,微风。
更多详细信息可以参考 [中国气象局](https://weather.cma.cn/web/weather/57494.html) 或 [墨迹天气](https://tianqi.moji.com/weather/china/hubei/wuhan)。
虽然它会回答错(因为查到的网站不行),但注意到它的可能性——一行代码带来 ReAct 模式,不需要自己去维护相关的 Prompt。
但这个教程只介绍了使用create_react_agent方法去创建一个 Agent,我想要更细节的内容,所以这里……不再深入了。
但这里仍旧提及一件事——tool 是直接绑定到 model 上的,这个功能是 LangChain 直接提供的,离开 LangGraph 也能用:
1 | |
ContentString:
ToolCalls: [{'name': 'tavily_search_results_json', 'args': {'query': '今天三亚天气'}, 'id': 'call_0_5ae8224b-2439-4afa-9d6e-35ccebd89617', 'type': 'tool_call'}]
实际上,这个功能来自 OpenAI 的 API 规范,兼容 OpenAI 的 API 的 AI 均能够使用此种方式。
但同时也注意——这里没有真的调用这个工具,AI 只是试图去调用它,真正调用这个工具是我们的“客户端”的任务,客户端调用工具后,将工具调用结果(成功或者失败)也放到会话历史中。
但根据我们目前学到的东西,无法自己实现create_react_agent……这个 agent 可能会对应这样一个图结构,但我不知道如何去定义它,如何去标识现在是否完成了执行。但是有方法看到这个图的结构:
1 | |
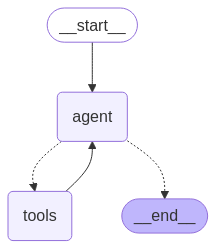
注意到,agent 连接到 tool 再连接回来,agent 同时也连接着 end,所以问题就是,何时是真正的 end?它是如何标识的?实际上我们知道它是如何标识的——当 agent 没有再调用工具而是开始返回内容的时候,但我不知道如何配置,这个就待后面实际去进行学习了,下一步是继续跟随它的教程去研究 RAG,RAG 是 Agent 的一种特定的应用场景,从 RAG 便能管中窥豹,看到工作流的更多的性质。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!