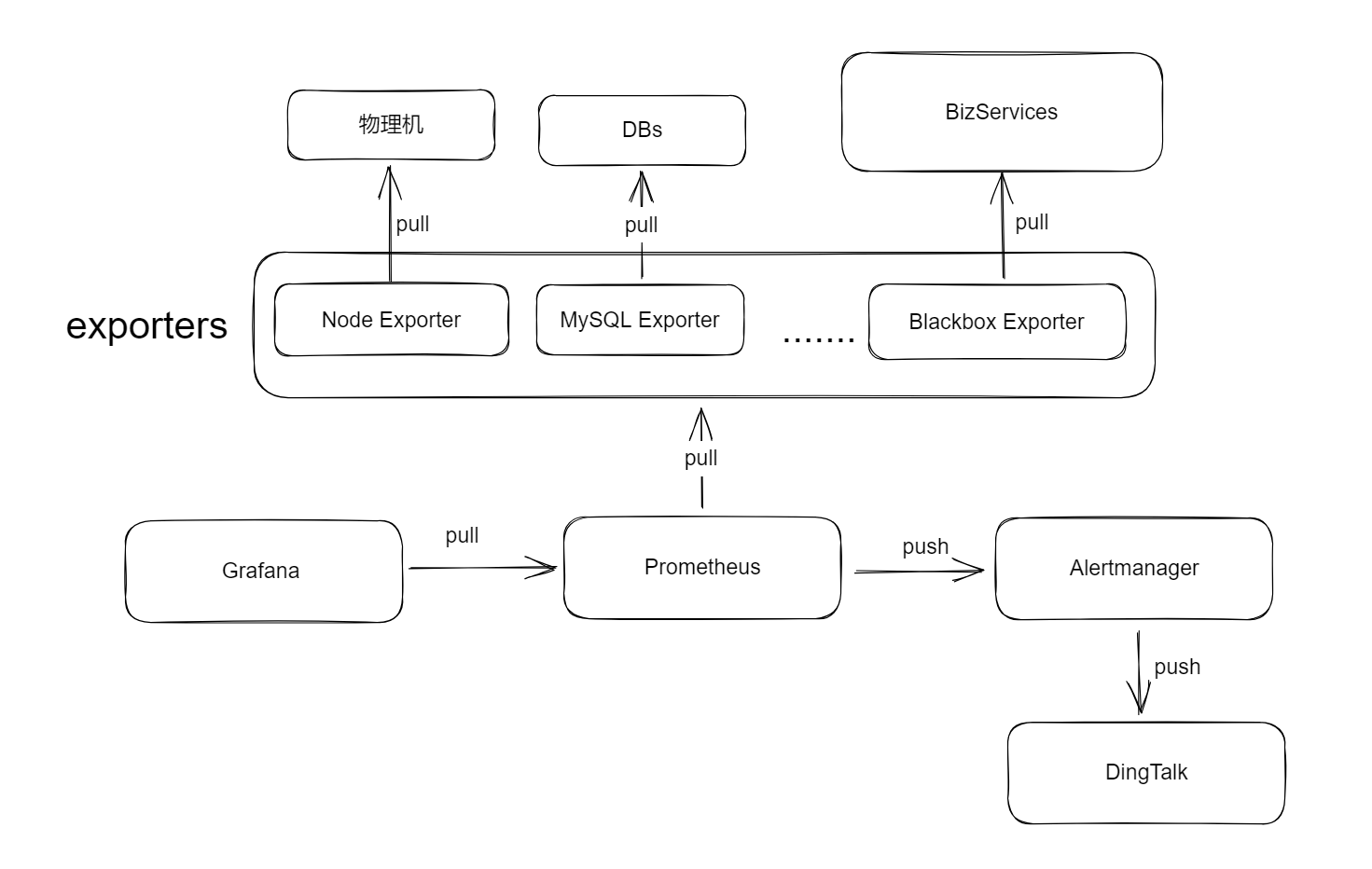
普罗米修斯,后面简称 prom,是一个分布式的监控平台,它有自己的服务端,通过拉 模式从各种客户端,如 spring 应用,中间件,mysql 等拉取信息,各种 exporter 是客户端和 prom 之间的 adapter。项目用到了 prom,所以这里学习一下做个笔记。
这篇笔记包括:
prom,grafana,alertmanager 环境搭建
node-exporter,nginx-prometheus-exporter, prometheus-nginxlog-exporter,blackbox-exporter 环境搭建和集成
redis exporter, mysql exporter 环境搭建和集成alertmanager 环境搭建,集成和使用
PromQL 入门和示例
prom, grafana grafana 是 prom 的客户端 ,它从 prom 上拉数据去展示,prom 不知晓 grafana 。
直接上 docker,使用 grafana 去连上 prom:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 version: "3" services: prometheus: image: prom/prometheus container_name: prometheus hostname: prometheus restart: always volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml ports: - "9090:9090" grafana: image: grafana/grafana container_name: grafana hostname: grafana restart: always ports: - "3000:3000"
其中 prom 配置文件内容为:
global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['172.17.0.1:9090' ]
job 是实例 instance 的集合,实例是监控的最小单元,任何指标都会被赋予 job 和 instance 标签去标识它来自哪个实例 。
执行 docker compose up -d,访问 grafanalocalhost:3000 admin/admin,在 connection 中添加 prom 的数据源,然后添加一个 dashboard,添加一个 code query:
alertmanager 参考 https://prometheus.io/docs/alerting/latest/overview/ 。
prom 负责拉取和存储数据,并在出现问题时推送告警给 alertmanager,alertmanager 将告警去重,分组,路由到特定处理逻辑。prom 知晓 alertmanager ,alertmanager 不知晓 prom。
The main steps to setting up alerting and notifications are:
Setup and configure the Alertmanager
Configure Prometheus to talk to the Alertmanager
Create alerting rules in Prometheus
部署 alertmanager 的 docker compose 如下:
alertmanager: image: prom/alertmanager container_name: alertmanager hostname: alertmanager restart: always environment: TZ: Asia/Shanghai ports: - "9093:9093" volumes: - "./alertmanager:/config" command: --config.file=/config/alertmanager.yml --log.level=info
alertmanager 需要配置告警路由和接受者:
route: receiver: 'dingtalk' repeat_interval: 1h group_by: [ serverity , alertname ]receivers: - name: 'dingtalk' webhook_configs: - url: '钉钉 webhook' send_resolved: true
关于路由和接受者的配置见 https://prometheus.io/docs/alerting/latest/configuration/#route 和 https://prometheus.io/docs/alerting/latest/configuration/#receiver 。路由是一个树结构,根节点必须匹配所有告警。后续有需要再研究。
prom 告警配置 prom 主动推送告警给 alertmanager,因此需配置 prom 去知晓 alertmanager ,以及配置 prom 的告警规则 :
rule_files: - "/etc/prometheus/rules/*.yml" alerting: alertmanagers: - scheme: http static_configs: - targets: [ 'alertmanager:9093' ]
以及需要配置告警规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 groups: - name: 实例存活告警规则 rules: - alert: 实例存活告警 expr: up == 0 for: 30s labels: serverity: Disaster annotations: summary: "节点失联" description: "节点断联已超过 1 分钟" - name: 内存告警规则 rules: - alert: "内存使用率告警" expr: round((node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 ,1) > 75 for: 30s labels: severity: warning annotations: summary: "服务器内存报警" description: "内存资源利用率大于 75%!(当前值:{{ $value }} %)" - name: 端点断连告警规则 rules: - alert: 端点断连告警 expr: probe_success == 0 labels: serverity: Disaster for: 30s annotations: summary: "端点断连告警" description: "端点断连已超过 1 分钟"
prom 会对每个告警规则的 expr 求值,如果求值得到的瞬时向量非空 且持续 for 中指定的时间,则认为需要告警,推送给 alertmanager。alertmanager 再推送给钉钉等接受者。
钉钉告警配置 TODO
node-exporter node-exporter 检测物理机的资源占用情况,因此需要进行本机安装。node-exporter 监听 9100 端口。
直接执行该 sh 即可安装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #!/bin/bash mv node_exporter-1.8.1.linux-amd64/node_exporter /usr/local/bincat <<EOF >/usr/lib/systemd/system/node_exporter.service [Unit] Descrption=https://prometheus.io [Service] Restart=on-failure ExecStart=/usr/local/bin/node_exporter --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service [Install] WantedBy=multi-user.target EOF enable node_exporter
此时curl localhost:9100/metrics便能看到结果。
在prometheus.yml下配置相应 job:
- job_name: 'some_node_exporter' static_configs: - targets: ['IP:9100' ]
nginx-exporter nginx 的 exporter 有两个:
nginx-prometheus-exporter,访问 nginx 直接暴露出来的接口获取指标,它可以部署在任意机器上
prometheus-nginxlog-exporter,修改 nginx 的访问日志格式,通过分析日志去得到各种类型请求的情况,需要部署在 nginx 所在机器上
nginx-prometheus-exporter 参照 https://blog.csdn.net/zls365365/article/details/134623254 。
nginx 自己有配置能暴露出当前状态为 HTTP 接口,但要和 prom 集成需要一个所谓的 nginx-prometheus-exporter去转换它的格式。
首先需要配置 nginx,在 nginx.conf 中加入:
location /nginx_status {stub_status on ;access_log off ;allow all;
使用 docker 部署nginx-prometheus-exporter:
nginx-prometheus-exporter: image: nginx/nginx-prometheus-exporter container_name: nginx-prometheus-exporter hostname: nginx-prometheus-exporter restart: always ports: - "9113:9113" command: -nginx.scrape-uri http://172.17.0.1:8080/nginx_status
然后在 prom 的配置文件中添加相应 job:
- job_name: 'nginx-prometheus-exporter' static_configs: - targets: ['nginx-prometheus-exporter 的 IP:PORT' ]
prometheus-nginxlog-exporter log-exporter 也可以使用 docker 部署,只要把 nginx 的日志 mount 给容器即可:
nginxlog-exporter: image: quay.io/martinhelmich/prometheus-nginxlog-exporter container_name: nginxlog-exporter hostname: nginxlog-exporter ports: - "4040:4040" volumes: - ./exporter.hcl:/etc/exporter.hcl - /var/log/nginx:/var/lib/nginx:ro command: ["-config-file" , "/etc/exporter.hcl" ]
配置文件 exporter.hcl:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 listen {
以及需要配置 nginx 的日志格式和 log exporter 匹配 :
http {log_format upstream_time '$remote_addr - $remote_user [$time_local ] ' '"$request " $status $body_bytes_sent ' '"$http_referer " "$http_user_agent " ' 'rt=$request_time uct="$upstream_connect_time " uht="$upstream_header_time " urt="$upstream_response_time "' ;
执行 curl localhost:4040/metrics即可。
配置 prom 的 job:
- job_name: 'prometheus-nginxlog-exporter' static_configs: - targets: ['prometheus-nginxlog-exporter 的 IP:PORT' ]
blackbox-exporter 参考 https://prometheus.io/docs/guides/multi-target-exporter/ ,https://github.com/prometheus/blackbox_exporter 。
The blackbox exporter allows blackbox probing of endpoints over HTTP, HTTPS, DNS, TCP, ICMP and gRPC.
blackbox exporter 可用来验证 HTTP 端口是否存活。blackbox exportter 生成自己使用所谓的 multi-target 模式,归根结底就是说该 exporter 只负责发请求,向谁发,何时发,全由 prom 去给定,在 prom 对该 exporter 的请求中给定在请求参数中,该 exporter 自己没有关于业务的任何配置 。请求类似:http://localhost:9115/probe?target=prometheus.io&module=http_2xx。
注意 blackbox 默认走的 IPV6 ,把它配置文件弄下来,检查modules.http_2xx.http.preferred_ip_protocol 是否为 ip4。
curl -o blackbox.yml https://raw.githubusercontent.com/prometheus/blackbox_exporter/master/blackbox.yml
使用 docker 部署:
blackbox-exporter: image: prom/blackbox-exporter container_name: blackbox-exporter hostname: blackbox-exporter restart: always ports: - "9115:9115" volumes: - ./blackbox.yml:/blackbox.yml:ro command: - --config.file=/blackbox.yml
prom 配置:
- job_name: 'blackbox-exporter' static_configs: - targets: ['172.17.0.1:9115' ]
注意该配置中不包含真正要监测的端点。要配置真正检测的端点,需要另行配置 job 去以特定查询参数去调 blackbox 去让它发请求:
- job_name: repo_alive metrics_path: /probe params: module: [http_2xx ]target: [https://github.com/prometheus/blackbox_exporter ]static_configs: - targets: ['172.17.0.1:9115' ]- job_name: github_alive metrics_path: /probe params: module: [http_2xx ]target: [https://github.com ]static_configs: - targets: ['172.17.0.1:9115' ]
但一个接口定义一个 job 有点麻烦,可以使用 prom 的 relabel 机制:
简单理解该 relabel 的话就是 target_label = source_label | replacement。如果要重命名 instance 的话是否必须得用 relabel?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 - job_name: blackbox-http metrics_path: /probe params: module: [http_2xx ]static_configs: - targets: - http://prometheus.io - https://prometheus.io - http://example.com:8080 relabel_configs: - source_labels: [__address__ ] target_label: __param_target - source_labels: [__param_target ] target_label: instance - target_label: __address__ replacement: 172.17 .0 .1 :9115
该项目接口响应码总为 200,实际响应码在 body 的 code 字段中,可以使用正则去检查请求是否正常。这个配置需要写在 blackbox 的配置文件中,新增一个 module,并配置 prom 去使用该 module 即可,参考https://github.com/prometheus/blackbox_exporter/blob/master/CONFIGURATION.md :
modules: http_body_2xx: prober: http http: fail_if_body_not_matches_regexp: - \"code\"\b*?:\b*?2\d\d preferred_ip_protocol: "ip4" http_2xx: prober: http http: preferred_ip_protocol: "ip4"
另一个更激进的利用 relabel 的配置如下,它利用正则去给每个实例取名字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 - job_name: blackbox-ping metrics_path: /probe params: module: [icmp ]static_configs: - targets: - ping_15$$172.31.129.15 - ping_251$$172.31.129.251 relabel_configs: - source_labels: [__address__ ] regex: .*?\$\$(.*) target_label: __param_target replacement: ${1} - source_labels: [__address__ ] regex: (.*?)\$\$.* target_label: instance replacement: ${1} - target_label: __address__ replacement: 172.17 .0 .1 :9115
处理 DNS 问题 blackbox exporter 默认会把域名转换成 IP 后再发送请求,这在服务器需要域名信息时会导致问题,要避免该情况,必须使用一个代理服务器,配置 blackbox exporter 容器使用该代理,并在 module 中配置 skip_resolve_phase_with_proxy 为 true,这里假设宿主机有一个 HTTP 代理,监听 8888 端口:
modules: nodns_body_2xx: prober: http http: preferred_ip_protocol: "ip4" fail_if_body_not_matches_regexp: - \"code\"\b*?:\b*?2\d\d proxy_url: http://172.17.0.1:8888 skip_resolve_phase_with_proxy: true
创建代理服务器可以使用 tinyproxy:
然后编辑/etc/tinyproxy/tinyproxy.conf,注释掉Allow 127.0.0.1使得允许所有连接,然后启动 tinyproxy:
systemctl enable tinyproxy
mysql exporter, redis exporter TODO
所有配置 docker-compose.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 version: '3' services: nginx-prometheus-exporter: image: nginx/nginx-prometheus-exporter container_name: nginx-prometheus-exporter hostname: nginx-prometheus-exporter restart: always ports: - "9113:9113" command: -nginx.scrape-uri http://172.17.0.1:10800/nginx_status nginxlog-exporter: image: quay.io/martinhelmich/prometheus-nginxlog-exporter container_name: nginxlog-exporter hostname: nginxlog-exporter ports: - "4040:4040" volumes: - ./exporter.hcl:/etc/exporter.hcl - /var/log/nginx:/var/lib/nginx:ro command: ["-config-file" , "/etc/exporter.hcl" ]prometheus: image: prom/prometheus container_name: prometheus hostname: prometheus restart: always volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml:ro - ./rules:/etc/prometheus/rules:ro ports: - "9090:9090" grafana: image: grafana/grafana container_name: grafana hostname: grafana restart: always ports: - "3000:3000" alertmanager: image: prom/alertmanager container_name: alertmanager hostname: alertmanager restart: always environment: TZ: Asia/Shanghai ports: - "9093:9093" volumes: - "./alertmanager:/config" command: --config.file=/config/alertmanager.yml --log.level=info blackbox-exporter: image: prom/blackbox-exporter container_name: blackbox-exporter hostname: blackbox-exporter restart: always ports: - "9115:9115" volumes: - ./blackbox.yml:/blackbox.yml:ro command: - --config.file=/blackbox.yml
prometheus.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['172.17.0.1:9090' ] - job_name: 'nginx-prometheus-exporter' static_configs: - targets: ['nginx-prometheus-exporter:9113' ]- job_name: nginxlog-exporter static_configs: - targets: - nginxlog-exporter:4040 - job_name: node162 static_configs: - targets: - 172.17 .0 .1 :9101 - job_name: 'blackbox-exporter' static_configs: - targets: ['blackbox-exporter:9115' ]- job_name: blackbox-http metrics_path: /probe params: module: [http_2xx ]static_configs: - targets: - baidu$$https://baidu.com relabel_configs: - source_labels: [__address__ ] regex: .*?\$\$(.*) target_label: __param_target replacement: ${1} - source_labels: [__address__ ] regex: (.*?)\$\$.* target_label: instance replacement: ${1} - target_label: __address__ replacement: blackbox-exporter:9115 - job_name: blackbox-ping metrics_path: /probe params: module: [icmp ]static_configs: - targets: - ping_self$$172.17.0.1 relabel_configs: - source_labels: [__address__ ] regex: .*?\$\$(.*) target_label: __param_target replacement: ${1} - source_labels: [__address__ ] regex: (.*?)\$\$.* target_label: instance replacement: ${1} - target_label: __address__ replacement: blackbox-exporter:9115 rule_files: - "/etc/prometheus/rules/*.yml" alerting: alertmanagers: - scheme: http static_configs: - targets: [ 'alertmanager:9093' ]
blackbox.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 modules: http_2xx: prober: http http: preferred_ip_protocol: "ip4" http_post_2xx: prober: http http: method: POST tcp_connect: prober: tcp pop3s_banner: prober: tcp tcp: query_response: - expect: "^+OK" tls: true tls_config: insecure_skip_verify: false grpc: prober: grpc grpc: tls: true preferred_ip_protocol: "ip4" grpc_plain: prober: grpc grpc: tls: false service: "service1" ssh_banner: prober: tcp tcp: query_response: - expect: "^SSH-2.0-" - send: "SSH-2.0-blackbox-ssh-check" irc_banner: prober: tcp tcp: query_response: - send: "NICK prober" - send: "USER prober prober prober :prober" - expect: "PING :([^ ]+)" send: "PONG ${1}" - expect: "^:[^ ]+ 001" icmp: prober: icmp icmp_ttl5: prober: icmp timeout: 5s icmp: ttl: 5
alertmanager/alertmanager.yml route: receiver: 'dingtalk' repeat_interval: 1h group_by: [ serverity , alertname ]receivers: - name: 'dingtalk' webhook_configs: - url: '钉钉 hook' send_resolved: true
rules/rule.yml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 groups: - name: 实例存活告警规则 rules: - alert: 实例存活告警 expr: up == 0 for: 30s labels: serverity: Disaster annotations: summary: "节点失联" description: "节点断联已超过 1 分钟" - name: 内存告警规则 rules: - alert: "内存使用率告警" expr: round((node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 ,1) > 75 for: 30s labels: severity: warning annotations: summary: "服务器内存报警" description: "内存资源利用率大于 75%!(当前值:{{ $value }} %)" - name: 端点断连告警规则 rules: - alert: 端点断连告警 expr: probe_success == 0 labels: serverity: Disaster for: 30s annotations: summary: "端点断连告警" description: "端点断连已超过 1 分钟" - name: 磁盘告警规则 rules: - alert: 磁盘空间不足 expr: round(100 * (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes, 1 ) > 75 for: 5m labels: severity: warning annotations: summary: "磁盘使用空间过高" description: "磁盘使用空间超过了 75%"
exporter.hcl 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 listen {
/etc/nginx/nginx.conf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 user www-data;worker_processes auto;pid /run/nginx.pid;include /etc/nginx/modules-enabled/*.conf ;events {worker_connections 768 ;http {sendfile on ;tcp_nopush on ;types_hash_max_size 2048 ;include /etc/nginx/mime.types;default_type application/octet-stream;ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3 ; ssl_prefer_server_ciphers on ;log_format upstream_time '$remote_addr - $remote_user [$time_local ] ' '"$request " $status $body_bytes_sent ' '"$http_referer " "$http_user_agent " ' 'rt=$request_time uct="$upstream_connect_time " uht="$upstream_header_time " urt="$upstream_response_time "' ;access_log /var/log/nginx/access.log;error_log /var/log/nginx/error .log;gzip on ;include /etc/nginx/conf.d/*.conf ;include /etc/nginx/sites-enabled/*;
PromQL 参考 https://prometheus.io/docs/prometheus/latest/querying/basics/ 。
PromQL 让用户能够实时地查询和聚合时间序列数据。PromQL 虽然第一眼看起来有点像 numpy,但其实它是更像 SQL 的,只不过没有显式的 select 和 where。
PromQL 的表达式可求值为四种类型:
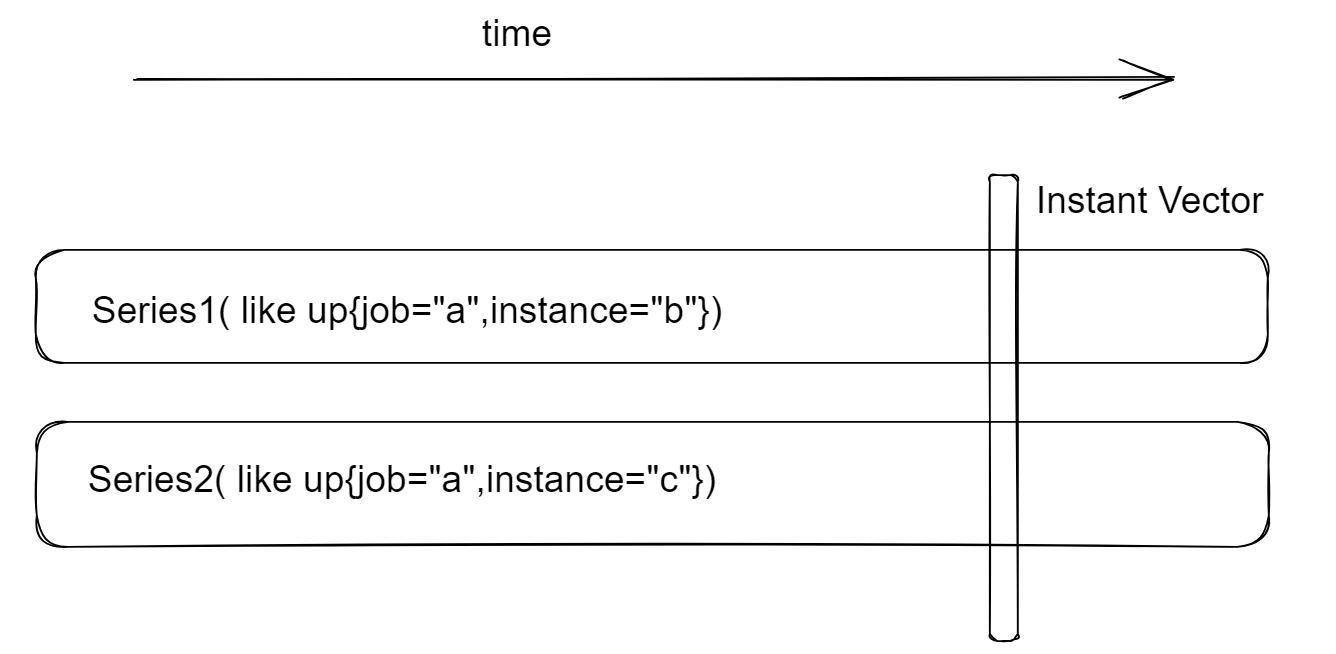
Instant Vector:瞬时向量,一个时间序列的集合,其中每个时间序列只有一个样本,他们的时间戳相同
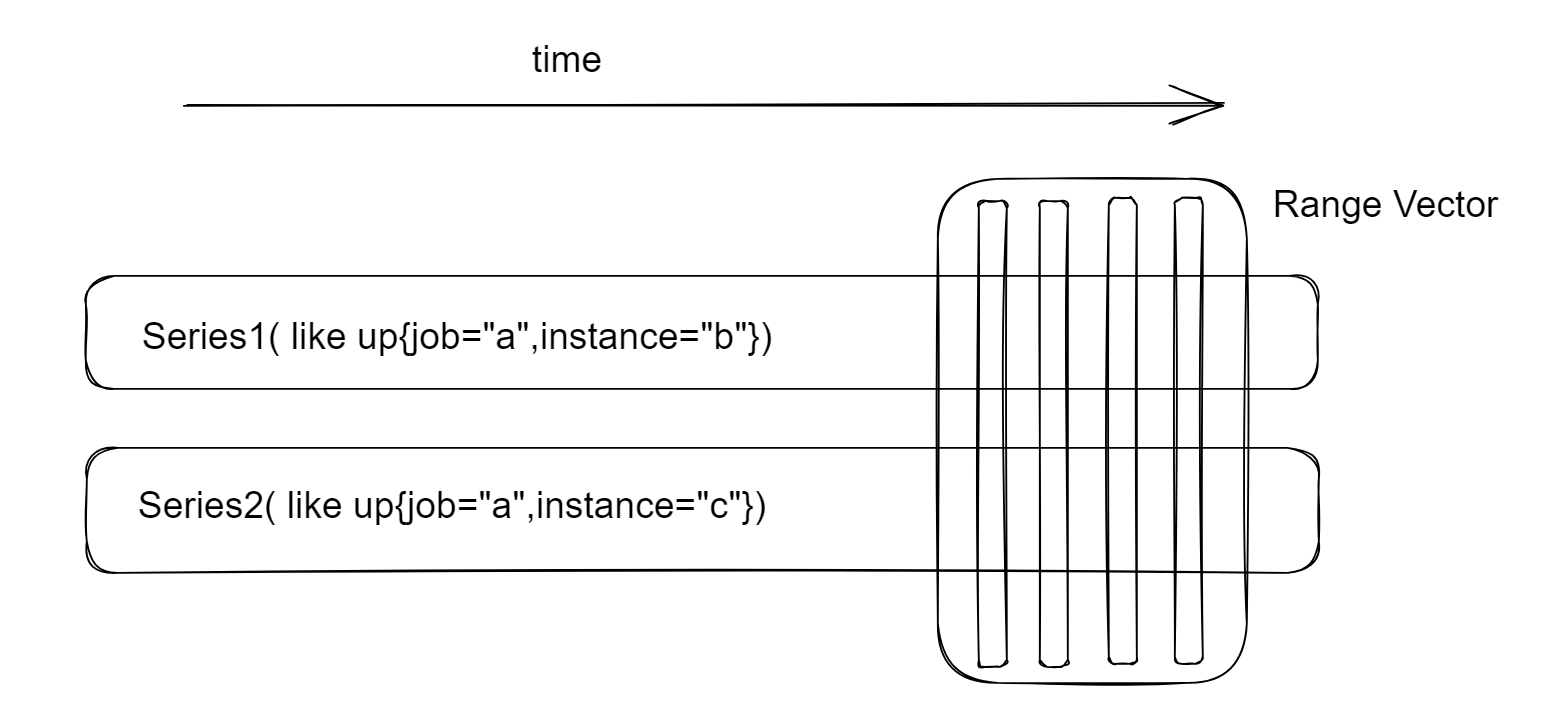
Range Vector:范围向量:一个时间序列的集合,每个时间序列都包含一个时间范围的数据点
Scalar:标量,一个浮点数
String:字符串,无实用意义
注意 PromQL 总是用 UTC 时区而非本机时区去操作的。
Instant vector selector
瞬时向量就像对每个时间序列都取同一个时间点的数据,下面的 PromQL 均取得的是瞬时向量:
up "a" } "db_.*" , job!="db_01_exporter" } "up" }
up{...}称为vector selector,它筛选的是时间序列 、仅有{}时,得到的时瞬时向量,所以这里叫他瞬时向量选择器。
Range vector selector
范围向量就像对每个时间序列取一定时间范围内点的数据,下面的 PromQL 均取得的是范围向量:
up{job=~"db_.*" }[1m] m: 5m]
范围向量不能显示为 graph ,也就是说在 grafana 和 prom 的 web 界面中,显示图表时不能使用范围向量类型的表达式。
graph 只接受瞬时向量 ,其将对于查询区间中的每一个时间点(如过去一小时的每一分钟)去执行该瞬时向量表达式,比如rate(http_requests_total[5m]),假设现在是 11 点,时间区间是过去一小时,则其会在 10:00,10:01,10:02 等时间点执行查询,获取这些时间点最近 5 分钟的请求速率,并以此绘制图表,
offset offset 修饰符能够修饰瞬时向量和范围向量,表示对当前时间戳进行一定偏移来进行查询:
up offset 10m
@ @ 修饰符能够修饰瞬时向量和范围向量,表示指定当前时间戳来进行查询,@接受一个 unix 时间戳,即一个从 1970 年 1 月 1 日至今的毫数:
up @ 1719370800 1719370800 1719370800 offset 5m
offset 和@位置可交换,offset 总是以@中的时间戳为基准做偏移。
算术操作符 算术操作符包括 +-*/%^,其中^是 pow。
算术操作符的两操作数可以为标量-标量,瞬时矢量-标量或瞬时矢量-瞬时矢量。操作数为两个矢量时,逐元素去操作(称为 vector matching),得到一个矢量,操作数为一个矢量一个标量时,把标量扩张成矢量去操作,得到一个矢量。结果矢量会抹掉指标名。
比较运算符 比较操作符同 C 语言。PromQL 的比较运算符,默认做的是筛选操作,就像 numpy 一样 。比如up == 0是筛选值为 0 的时间序列。要不做筛选而是逐维度去做比较,在操作符后加上 bool修饰符,如 up == bool 0,这样会得到所有的名称为 up 的时间序列,其中值原本为 1 的值为 0,原本为 0 的为 1。PromQL 认为 0 是 false,1 是 true 。
比较运算符同样支持标量-标量,瞬时矢量-标量或瞬时矢量-瞬时矢量。操作数为两个标量时,修饰符bool必须给定,操作数为两个矢量时,逐维度作比较,筛选比较成功的左操作数 ,比如(up + 1) > up,返回值为 1 和 2。
如果修饰符bool被给定,丢弃指标名。
集合操作符 集合操作符不改变数据的值,而是以指标名、所有标签为标识符做集合操作。集合操作符包括 and,or,unless,分别为交集,并集,差集。
函数 PromQL 可以认为是强类型的,它的函数接受参数和返回值的类型均被明确规定。函数定义可以参照 https://prometheus.io/docs/prometheus/latest/querying/functions/ 。
所有函数都返回瞬时向量 。要得到范围向量需要利用子查询。
Prom 允许嵌套的查询,如rate(node_disk_written_bytes_total[5m]),在这里node_disk_written_bytes_total[5m]是子查询。
子查询如果没有给定范围,则其返回的必定是瞬时向量,需要给定范围才能得到范围向量。
node_disk_written_bytes_total[5m] m: 5m] m: 5m]) m: 5m])[10h: 1h]
是否可以说,函数调用的语法其实是<函数名>(<函数参数>)[ [<范围>:<步长>] ]?
时间范围 Prometheus 的时间范围有点迷惑,如[24h:6h],一般就会想到,比如现在是 UTC 时间 13 点,它会取到 13 点,7 点,1 点,昨天 19 点,但它行为似乎不是这样——它实际上会做一个“对齐”,取 12 点,6 点,0 点和昨天 18 点数据。要验证这一点:
对齐的方式似乎是从 1970 年 1 月 1 日开始去按步长走,得到最接近当前时间的时间戳并以它作为最后一个时间戳,然后按步长往前走。
比如,当前是 1719475581(2024-06-27 08:06:21),设置步长为1h1m1s,即3661,最近的时间戳为 1719475581 - 1719475581 % 3661 = 1719472853(2024-06-27 07:20:53)。
因此,步长设置为6h时,最近的小时数会是 0、6、12、18,步长设置为24h或1d时,最近的小时数会是 0,即每日开始时间,因此[1d:1d]取得的就是本日开始时间。
步长设置为更长,如1w时也是如此。
vector matching TODO https://prometheus.io/docs/prometheus/latest/querying/operators/#vector-matching-keywords
group 修饰符 TODO…
示例 TODO