在上一家公司里,我根据需求使用 FastExcel 去抽象出了一个 excel 导出工具类,但在其中并没有去深入了解 Excel 的操作,而现在时机已到。
Java 处理 Excel 时,仍旧是使用最传统的 POI 较多(不是舰 C 的 那只 ),POI 的 官网 见此,似乎没有成体系的文档 ,只有一些用例,但感觉这或许已经足够。
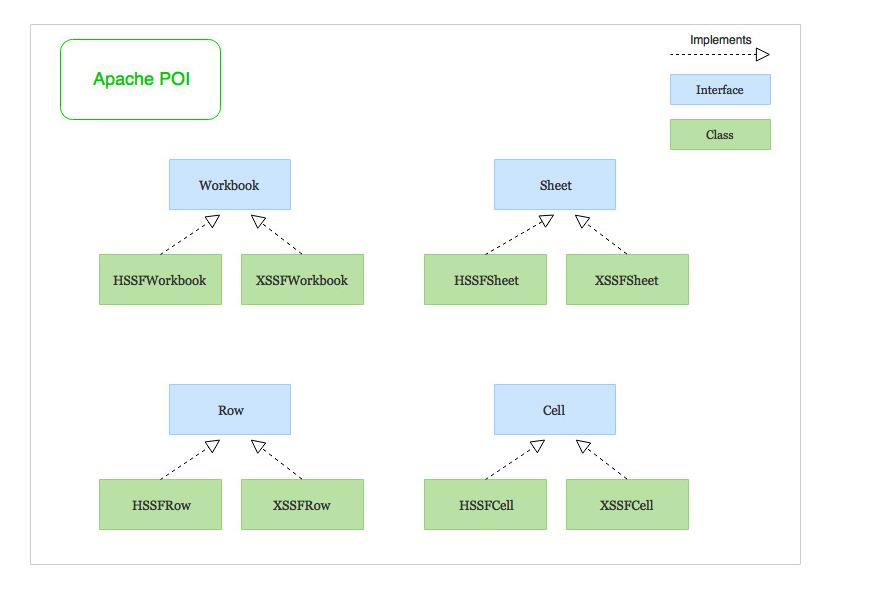
POI 是一个用于处理 word,excel,ppt 等 office 文件格式的巨型的工具库,但下面所说的 POI 指的都是其中操作 Excel 的部分——HSSF(对应 xls)和 XSSF(对应 xlsx),引入 poi 只需要引入 poi-ooxml 依赖(它包括 poi):
<dependency > <groupId > org.apache.poi</groupId > <artifactId > poi-ooxml</artifactId > <version > 5.2.2</version > </dependency >
下面尝试去专注这样几个场景:
数据集的导入:即前端上传一个规范的 Excel 文件,其包含表头,每一行为一个实体 ,行数不定,需获取整个实体集合
数据集的导出:返回给前端一个规范的 Excel 文件,其包含表头,每一行为一个实体,行数不定
单个数据的导入:前端上传一个格式固定 的 Excel 文件,整个 Excel 作为一个实体
单个数据的导出(或者按照模板导出):返回给前端一个格式固定的 Excel 文件,使用单个实体填充其中特定格
POI 的组成 POI 对 Excel 的抽象有四个关键的类:Workbook,Sheet,Row 和 Cell,其中,Wookbook 代表整个 Excel 文件,Sheet 代表 Excel 中的一个表格(每一个 Excel 文件都包含多个表格,其通过左下角的选项卡进行切换),Row 代表一个表格中的一行,Cell 代表一个单元格。
应当避免使用具体的 HSSF 和 XSSF 类以使代码更抽象,且同时适配 xls 和 xlsx 文件。
下面的实例主要来自官方文档的 quick-guide,见文章末尾链接。
数据集的导入 数据集导入场景要求读取现存的 Excel 文件并识别相关的 Bean,一般思路是:
通过 Excel 文件/流创建 Workbook
获取表头,知晓每一列对应的字段(当然,也可以用列数来直接区分)
获取剩余每一行并对其进行处理
Workbook 能通过 File,InputStream 去构造,比如下面的代码从用户上传的文件中拿到流,并构造 Workbook 和 Sheet(假设是第一个 Sheet)。
下面通过一个轮子来描述数据集的导入,其将一个 Excel 转换成List<Map<String, Object>>,其中每一个 Map 为一个实体,key 为表头(因此该方法操作的 Excel 必须要有表头,且表头长度必须为 1,这是最简单的情况了)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 List<Map<String, Object>> excelToCollection (InputStream in, int sheetIndex) throws IOException {Workbook wb = WorkbookFactory.create(in);Sheet sheet = wb.getSheetAt(sheetIndex);int firstRowNum = sheet.getFirstRowNum();int lastRowNum = sheet.getLastRowNum();Row head = sheet.getRow(firstRowNum);false )return IntStream.rangeClosed(firstRowNum + 1 , lastRowNum)new HashMap <>();false ).forEach(cell -> {return obj;getCellValue (Cell cell) {switch (cell.getCellType()) {case _NONE: return null ;case BLANK: return "" ;case ERROR: return cell.getErrorCellValue();case STRING: return cell.getStringCellValue();case BOOLEAN: return cell.getBooleanCellValue();case NUMERIC:case FORMULA: return cell.getNumericCellValue();default :throw new RuntimeException ("无法识别" );
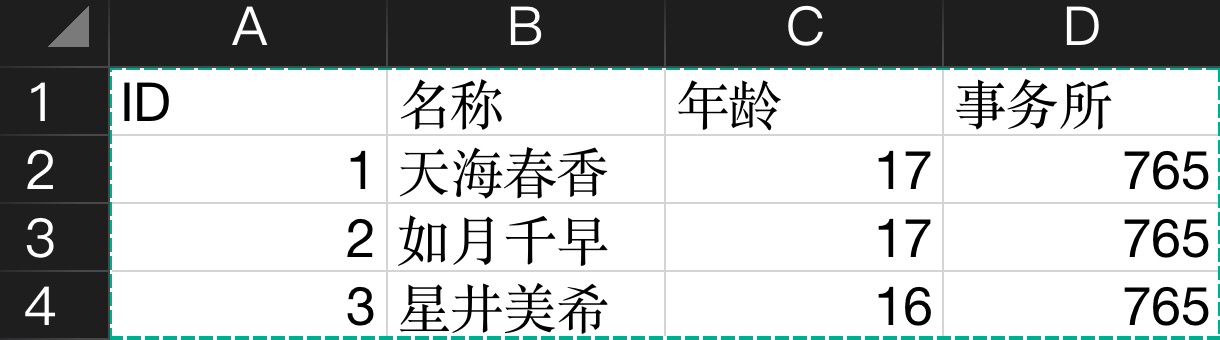
对下面这个 Excel:
其将得到这样的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [ { "名称" : "天海春香" , "ID" : 1.0 , "事务所" : 765.0 , "年龄" : 17.0 } , { "名称" : "如月千早" , "ID" : 2.0 , "事务所" : 765.0 , "年龄" : 17.0 } , { "名称" : "星井美希" , "ID" : 3.0 , "事务所" : 765.0 , "年龄" : 16.0 } ]
容易发现,对于这样的简单 Excel,可以要求使用者去直接给出一个(Row, Headers) -> T,从而来方便生成List<T>。
数据集的导出 导出数据集就更加容易一些——生成表头,然后后续迭代数据集,一个元素一列即可(最麻烦的地方在于处理导出的类型,这里一股脑用字符串),下面的代码直接将一个元素的列表转为 Workbook,然后再另行导出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 Workbook createByCollection (Collection<?> elems) throws IllegalAccessException, IOException {if (lst.isEmpty()) {throw new IllegalArgumentException ("?" );0 ).getClass().getDeclaredFields();for (Field field : fields) {true );Workbook workbook = WorkbookFactory.create(true );Sheet sheet = workbook.createSheet();Row head = sheet.createRow(0 );for (int i = 0 ; i < fields.length; i++) {for (int i = 0 ; i < lst.size(); i++) {int rowNum = i + 1 ;Row row = sheet.createRow(rowNum);Object elem = lst.get(i);for (int j = 0 ; j < fields.length; j++) {return workbook;
导出时使用 Workbook 的 write 方法,该方法接受一个输出流,下面的代码可以将 Workbook 转换成 Resource,从而方便在 Spring MVC 的情境中使用(效率存疑)。
ByteArrayOutputStream arrayOutputStream = new ByteArrayOutputStream ();OutputStream output = new BufferedOutputStream (arrayOutputStream);return new ByteArrayResource (arrayOutputStream.toByteArray());
单个数据的导入导出 单个数据的导入导出相较于数据集的导入导出,差别是它的格式一般是固定的,这就是说数据的特定字段一般来说会对应 Excel 的特定位置 ,这说明两件事:
我们需要“随机访问” Excel 的任意行列
Excel 中一定有东西是不变的,也就是说在构造 Excel 时,可以为这些不变的地方创建一个模板
因此,归结出来,单个数据的导入导出情景详细描述如下,两者非常相像:
导入:接受一个固定格式的 Excel,获取其中特定位置的值并构造一个实体
导出:以一个现有的 Excel 作为模板,使用一个实体去填充其中特定位置的值
下面的代码实现了一个写入特定位置的方法,用户调用时指定位置到操作的映射。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void setExcelValue (Sheet sheet, Map<String, Consumer<Cell>> cells) {CellAddress cellAddress = new CellAddress (cellAddressStr);Row row = sheet.getRow(cellAddress.getRow());if (row == null ) row = sheet.createRow(cellAddress.getRow());Cell cell = row.getCell(cellAddress.getColumn());if (cell == null ) cell = row.createCell(cellAddress.getColumn());new HashMap <String, Consumer<Cell>>(){{"B1" , cell -> cell.setCellValue("天海春香" ));"D1" , cell -> cell.setCellValue(765 ));"B4" , cell -> cell.setCellValue(17 ));
这里涉及到的内容是比较少的,对于更加复杂的表格形式,以及样式等都没有顾及到,在性能上也需要进一步研究,等真正遇到时再说吧。
参考阅读