开始根据《深入理解 Hadoop》去学习 MapReduce 的编程模式。MapReduce 的接口看上去是十分简单的,但显然,为了尽量快地能够将其用于工程实践,首先学点模式肯定是最合适的 。
这里特意使用“开发模式 ”,而非“编程模式”,“设计模式”,这是因为 MapReduce 的编写中,Mapper,Reducer 的设计和 Job 的配置是密不可分的,并且需要程序员对 MapReduce 全流程及其原理有一定的理解,这里涉及的东西显然不止于编程 (下面的实际内容也偏向理论和原理更多,没多少代码,代码也都很简单),因此我使用“开发模式”这一说法。
MapReduce 中主要包含 6 个用户可以自定义的组件/角色,按照数据的流向为顺序,他们是——
InputFormat
Mapper
Partitioner
Combiner
Reducer
OutputFormat
各种开发模式主要相关的是中间四个角色,即 Mapper,Combiner,Partitioner,Reducer,先对它们进行了解,同时辅以一些代码示例,使用 Java 和 Scala 表达,之后或许会一直使用 Scala,很性感。
Hive 证明,SQL 能翻译成 MapReduce 程序,但反过来说,我们也可以使用 SQL 来说明 MapReduce 的一些模式 ——
SELECT :即 Map 操作,筛选/构造特定列WHERE :即 Filter 操作,筛选特定行(即特定 KV 对,称作行是因为它符合直觉一些)AGGREGATION :即 Reduce,聚集操作,将一个分组聚合成一个值,比如 MAX,MIN,SUM,COUNT 等SORTING :对输出结果进行排序JOIN :根据不同表/查询结果的相同列进行连接操作
十分显然,Map 阶段可以执行 SELECT,WHERE 操作,Map 阶段同时负责以及 GROUP BY——返回值的 KEY 就是用于分组的字段;而 Reduce 阶段执行的则是 AGGREGATION 。SORTING 和 JOIN 不那么显然,之后再说。排序当前猜测是 Partitioner 执行的。
当然,MapReduce 的能力绝对不限于 SQL,这么说只是因为它更容易理解罢了。我实际上确实有一些怀疑——使用函数式编程的术语对 MR 进行表述是否比 SQL 更容易理解和贴合实际?
学习过程中将试图使用该书中所提到的 航空数据 ,其为标准的 csv 格式(以及一些 html 文档),解压后得到的 csv 文件内容类似下面,首行是表头,应当剔除掉 。
Year,Month,DayofMonth,DayOfWeek,DepTime,CRSDepTime,ArrTime,CRSArrTime,UniqueCarrier,FlightNum,TailNum,ActualElapsedTime,CRSElapsedTime,AirTime,ArrDelay,DepDelay,Origin,Dest,Distance,TaxiIn,TaxiOut,Cancelled,CancellationCode,Diverted,CarrierDelay,WeatherDelay,NASDelay,SecurityDelay,LateAircraftDelay
字段名称
描述
Year
该航班的年份(1987 到 2008)
Month
月份(1-12)
DayofMonth
月份的日期(1-31)
DayOfWeek
周几,1=周一,7=周日
DepTime
本地时区的航班起飞时间,HHMM 格式,前不补零,如 753 表示 07:53,1503 表示 15:03
CRSDepTime
原定起飞时间,格式同上
ArrTime
实际到达时间,格式同上
CRSArrTime
原定到达时间,格式同上
UniqueCarrier
航空公司代码
FlightNum
航班的唯一标识
TailNum
飞机的唯一标识
ActualElapsedTime
实际飞行时间(分)
CRSElapsedTime
原定飞行时间(分)
AirTIme
总的飞行时间(分)
ArrDelay
到达延迟时间(分)
DepDelay
起飞延迟时间(分)
Origin
起飞机场代码
Dest
目的地机场代码
Distance
总飞行距离(英里)
TaxiIn
航班到达期间,出租车进入时间(分)
TaxiOut
起飞期间,出租车离开时间(分)
Cancelled
航班是否取消,1=是,0=否
CancellationCode
取消原因,A=承运,B=天气,C=NAS,D=安全问题
Diverted
是否改道,1=是,0=否
CarrierDelay
航空公司造成的延误时间(分)
WeatherDelay
天气造成的延误时间(分)
NASDelay
国家空管系统(NAS)造成的延误时间(分)
SecurityDelay
安全原因造成的延误时间(分)
LateAircraftDelay
该航班在上个机场到达晚点而造成在本机场到达延迟时间(分)
一切空值都使用 NA 表示,各个字段都需要考虑 NA 的情况 。
这里提供一个类来为原始数据建模,方便能快速和类型安全地取得数据,取得特定列的数据的代码见下面 SelectClause 的使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import java.util.function.Function;public enum AirlineCol {0 ),1 ),2 ),3 ),4 ),5 ),6 ),7 ),8 ),9 ),10 ),11 ),12 ),13 ),14 ),15 ),16 ),17 ),18 ),19 ),20 ),21 ),22 ),23 ),24 ),25 ),26 ),27 ),28 );public final int index;int index) {this .index = index;public static class ColGetter {private final Function<AirlineCol, String> fn;private ColGetter (Function<AirlineCol, String> fn) {this .fn = fn;public String getCol (AirlineCol colEnum) {return fn.apply(colEnum);public static ColGetter get (String[] cols) {return new ColGetter ((col) -> cols[col.index]);
下面,按照各种子句来一一学习各种开发模式,其中穿插着一些关于 MR 本身的概念。
Mapper——SELECT 和 WHERE 典型的 MapReduce 程序主要包含两个阶段——Map 阶段和 Reduce 阶段,其中包含四个角色——Mapper,Combiner,Partitioner,Reducer。
但并非所有 Job 都需要所有的这些角色:倘若不需要 Reduce 阶段,这是说,倘若作业仅使用 SELECT 和 WHERE 就能够表述的话,仅需要自定义 Mapper 角色即可。这种情况包括对原始数据进行清理,格式化,筛选等操作。
SELECT 子句(flatMap 操作) SELECT 子句用于筛选特定列,更准确的说是将每行原数据映射成为新数据。
考虑这样一个需求——将原数据转换成下面格式的数据:
航班的日期,格式为年/月/日
周几
预计起飞时间
预计到达时间
起飞机场的代码
到达机场的代码
航班总里程
实际飞行时间
计划飞行时间
起飞延迟时间
到达延迟时间
解决方法非常显然——获取每一行数据,通过原数据构造所需新数据,向上下文中写入新数据,这是一个典型的 SELECT,只不过做了一些字段拼接和转换之类的操作罢了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 import org.apache.commons.lang3.StringUtils;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;import java.util.StringJoiner;public class SelectClause {public static class SelectClauseMapper extends Mapper <LongWritable, Text, NullWritable, Text> {private static final Text outputV = new Text ();@Override protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException {if (value.toString().startsWith("Year" )) {return ;ColGetter cols = AirlineCol.build(value.toString().split("," ));String date = new StringJoiner ("/" )2 , "0" ))2 , "0" ))String dayOfWeek = cols.getCol(AirlineCol.DayOfWeek);String depTime = StringUtils.leftPad(cols.getCol(AirlineCol.DepTime), 4 , "0" );String arrTime = StringUtils.leftPad(cols.getCol(AirlineCol.ArrTime), 4 , "0" );String origin = cols.getCol(AirlineCol.Origin);String dest = cols.getCol(AirlineCol.Dest);String distance = cols.getCol(AirlineCol.Distance);String actualElapsedTime = cols.getCol(AirlineCol.ActualElapsedTime);String CRSElapsedTime = cols.getCol(AirlineCol.CRSElapsedTime);String depDelay = cols.getCol(AirlineCol.DepDelay);String arrDelay = cols.getCol(AirlineCol.ArrDelay);String result = new StringJoiner ("," )public static void main (String[] args) throws IOException, InterruptedException, ClassNotFoundException {Job job = Job.getInstance();0 );new Path (args[0 ]));new Path (args[1 ]));true ) ? 0 : 1 );
非常有趣的是,在本地跑 1987.csv 的时候,它切分了 4 个 Split,这说明本地的块大小默认为 32M,这是很合理的,因为在本地一般执行的是测试数据,量一般不大,同时又要照顾一下并发测试的需求。
配置项 代码本身没有什么麻烦的地方,主要是配置部分有很多需要学习的地方,虽然已经学过一些了,但我认为重复一次是好主意。setJar 之类的方法先略过——
setInputFormatClass,设置 InputFormat,默认值为 TextInputFormat,这里显式地设定了。TextInputFormat 逐行读取数据,对压缩文件能透明地处理。InputFormat 的泛型需和 Mapper 的输入 KV 匹配 (不匹配也没有关系,比如之前的代码有继承Mapper<Object, Text, ..., ...>的,使用更广泛的类型并不会报错。
TextInputFormat的签名为class TextInputFormat extends FileInputFormat<LongWritable, Text>,注意它不带泛型 ,所以让 Mapper 的输入有一定的强制性。
setOutputFormatClass,设置 OutputFormat,OutputFormat 决定输出时的行为,比如输出的格式,位置等(HDFS,数据库,第三方系统……),默认值为 TextOutputFormat,其默认行为将把输出数据一行一行地输出到不压缩的文本文件中。
TextOutputFormat的签名为class TextOutputFormat<K, V> extends FileOutputFormat<K, V>,它的类型参数仍旧没有给定 ,所以给 Reducer(或者 Mapper,如果没有 Reducer 的话) 输出类型的设定是比较自由的。
setMapOutputKeyClass和setMapOutputValueClass,设置 Mapper 输出值的类型,需和 Mapper 的输出 KV 匹配。这两个配置显然被OutputFormat所使用以用于序列化 Mapper 的输出值。setOutputKeyClass,setOutputValueClass同理,设置 Reducer 输出值的类型。
setMapperClass,字面意思。
setNumReduceTasks,设置 Reducer 的数量,设为 0 以避免 Reduce 阶段。
waitForCompletion,提交任务,参数为 true 表示打印日志到控制台。
关于 OutputKey 和 OutputValue 设置的问题,最佳实践是无论任何时候都给定 Map 和 Reduce 输出的 Class。
其实 OutputKeyClass,OutputValueClass,MapOutputKeyClass,MapOutputValueClass 这四个类并非一定要配置,它们究竟是否被使用取决于使用的 OutputFormat 。
默认的 TextOutputFormat 不会使用这几个类的信息 ——它的实现中直接调用了 K,V 对象的 toString 方法,并未使用上面的配置,仅仅是使用 instanceof 规定了 NullWritable 的情况 ,因此使用 TextOutputFormat 时,只有 Mapper 和 Reducer 的输出结果对实际的输出格式有影响,上面的配置不产生任何影响。
但是,不能靠特例来投机取巧,试图少敲几行代码,这增大了心智负担,在进行配置时需要强迫人去了解各种 OutputFormat 的具体实现乃至源码。因此,应当保证一致性,无论何种情况都给定 Mapper 和 Reducer 输出值的类型配置,以减少心智负担 ,且这样绝对不会抛出运行时异常,只要配置的没有错误的话。
顺带一提,书中说因为 Mapper 和 Reducer 的泛型会被擦除,所以无法在运行时知道 Mapper 和 Reducer 的输出的类型,所以需要手动设定。这说法是错误的——泛型实现类的泛型是不会被擦除的,在运行时能够获取到 。
运行方法 在本地执行时非常方便,在 IDEA 的 Run Configuration 中配置 CLI 参数为输入输出路径,点击 Run 即可,因此不表。
在集群上运行时需要打 jar 包,考虑到现在是容器化的时代,应当让打出来的 jar 包包含所有依赖,以使其能够在无任何依赖的情况下执行,不需要在 Hadoop 集群上添加依赖库(当然,至少学习情况下应该这样……不知道生产环境怎么处理)。为此,需要在 pom 下添加下面的配置——
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <build > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <configuration > <source > 8</source > <target > 8</target > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-assembly-plugin</artifactId > <version > 2.4.1</version > <configuration > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > </configuration > </plugin > </plugins > </build >
然后,执行mvn package打包,丢到集群里,用hadoop jar /path/to/jar SelectClause /hdfs/path/input /hdfs/path/output命令来执行 jar 包。注意 output 文件夹需不存在,为空也不行。
使用 1987 和 1988 两年的数据作为输入,通过日志能够发现 2 个 bz2 文件构造了 2 个 split(即使它解压后比 128M 大得多!)。待运行完毕后,能看到目录下生成了 2 个 Map 结果文件——
[root@hive share]# hdfs dfs -ls /output-03 -05 08:57 /output/_SUCCESS-03 -05 08:57 /output/part-m-00000 -03 -05 08:56 /output/part-m-00001
输出内容的顺序是不一定的,比如可能 00000 文件是 1988,00001 是 1987 年的数据。
WHERE 子句(filter 操作) 现在又来了一个需求——筛选 出飞机到达或起飞的实际时间延迟超过 n 分钟的航班,同时标识航班推迟的时刻——是在起点推迟(飞机起飞慢了),还是在目的地推迟(飞机到达慢了),还是都有推迟,分别使用 O,D,B 表示。显然该操作需要结合 SELECT 和 WHERE 子句。
使用简写字母表示的目的是为了尽可能减少数据长度,从而减少 IO。
该需求同时要求延迟时间 n 要能够通过外部自定义而非硬编码,这一点通过 Configuration 类 做到。每一个 Task,无论是 Mapper 还是 Reducer,在运行时都能够访问到一个所谓的 Configuration 的实例,其数据是在提交任务时给定的 。因此,在提交任务时设置任务所需要的配置(hadoop jar 的-D 参数可以用来配置它)就成为可能。
WhereClause 的代码见此,试着使用 Scala 来写,确实更清爽很多,但仍旧完全是命令式的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import org.apache.hadoop.fs.Path import org.apache.hadoop.io.{LongWritable , NullWritable , Text }import org.apache.hadoop.mapreduce.lib.input.{FileInputFormat , TextInputFormat }import org.apache.hadoop.mapreduce.lib.output.{FileOutputFormat , TextOutputFormat }import org.apache.hadoop.mapreduce.{Job , Mapper }import org.apache.hadoop.util.GenericOptionsParser class WhereClauseMapper extends Mapper [LongWritable , Text , NullWritable , Text ] private var delayInMinutes: Int = 0 ;private val outputK = NullWritable .getprivate val outputV = new Text ()override def setup Mapper [LongWritable , Text , NullWritable , Text ]#Context ): Unit = {"map.where.delay" , 1 )override def map LongWritable , value: Text , context: Mapper [LongWritable , Text , NullWritable , Text ]#Context ): Unit = {if (value.toString.startsWith("Year" )) {return val cols = SelectClause .parse(value.toString).split("," )val depDel = cols(8 ).toIntOption.getOrElse(0 )val arrDel = cols(9 ).toIntOption.getOrElse(0 )if (depDel < delayInMinutes && arrDel < delayInMinutes) {return val resultStr = cols.mkString("," ) + {if (depDel >= delayInMinutes && arrDel >= delayInMinutes) ",B" else if (depDel >= delayInMinutes) ",O" else if (arrDel >= delayInMinutes) ",D" else "" object WhereClause def main Array [String ]): Unit = {val parser = new GenericOptionsParser (args)val inputPath +: outputPath +: _ = parser.getRemainingArgs.toSeq.map(new Path (_))val job = Job .getInstance(parser.getConfiguration)WhereClause .getClass)TextInputFormat ])TextOutputFormat [NullWritable , Text ]])NullWritable ])NullWritable ])WhereClauseMapper ])0 )FileInputFormat .setInputPaths(job, inputPath)FileOutputFormat .setOutputPath(job, outputPath)System .exit {if (job.waitForCompletion(true )) 0 else 1
首先不设置map.where.delay,调用hadoop jar xx.jar WhereClause /data/sampledata /output,能看到 Map 前后 Record 数量分别为 6513924,6513883,没有筛选掉多少,这说明只有极少数的航班的延误时间能够小于 1 分钟;然后设置该配置,调用hadoop jar xx.jar WhereClause -D map.where.delay=100 /data/sampledata /output,会发现 Map 后的 Record 数量为 2630774,筛选了超过一半的航班(这延误率有点夸张吧 hhh)。
关于 GenericOptionParser 注意!这里的-D map.where.delay=100,对它的解析并非是hadoop jar命令的结果,而是在 Driver 类中所使用的 GenericOptionParser,它负责解析出一些常用的配置。hadoop jar的语法为hadoop jar <jar> [mainClass] args...,这里的 args 直接作为控制台参数传递给 Main 方法。
GenericOptionParser一般来说仅用于传递自定义的参数-D <name>=<value>,或者传递第三方库,后者为了方便不进行使用。
然后,重复一遍使用 GenericOptionParser 后 Driver 的样板(这里其实有很多“个性”,称不上样板),我喜欢样板——
使用控制台参数创建 GenericOptionParser
从 GenericOptionParser 中解构出 Configuration 和 inputPath,outputPath
根据 Configuration 创建 Job
通过 Class 设置 Jar
设置 InputFormat,OutputFormat
设置 MapOutputKey,MapOutputValue,OutputKey,OutputValue
设置 Mapper,Reducer(如果没有 Reducer,设置 Reducer task 数目为 0)
使用 FileInputFormat,FileOutputFormat 的静态方法设置输入路径和输出路径
提交任务
Reducer——GROUP BY,AGGREGATION 常用的聚合查询包括聚集函数,如 SUM,COUNT,MAX,MIN 等,以及两个子句 GROUP BY,HAVING。
但在此之前,我们先来看看在编程语言中的集合的 GroupBy 操作。Haskell 的 GroupBy 并不典型,这里看 Scala 的。
关于 Scala 和 SQL 的 Group By 操作 Scala 中,集合的 GroupBy 操作的签名为——
// 集合包含元素类型为 A def GroupBy [ K ] ( f : A => K ) : Map [ K , C ] // C 是原集合的类型,如 List [ A ]
函数 f 用于构造 key,得到相同 key 的实体会被分到同一个组中。
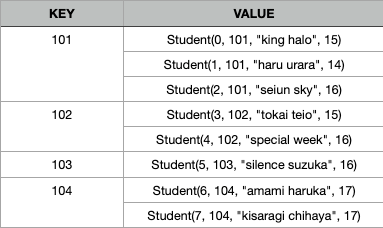
考虑一个学生实体及相关的数据。
case class Student (id : Int , classId : Int , name : String , age : Int )val datas = List (Student (0 , 101 , "king halo" , 15 ),Student (1 , 101 , "haru urara" , 14 ),Student (2 , 101 , "seiun sky" , 16 ),Student (3 , 102 , "tokai teio" , 15 ),Student (4 , 102 , "special week" , 16 ),Student (5 , 103 , "silence suzuka" , 16 ),Student (6 , 104 , "amami haruka" , 17 ),Student (7 , 104 , "kisaragi chihaya" , 17 )
对其调用groupBy(_.classId)后,会得到——
然后,试图统计每个班级的平均年龄以及该班级的所有学生的 id(的拼接),全部代码为——
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def average List [Int ]) : Double = {val (sum, len) = lst.foldLeft((0 , 0 )){case ((sum, len), elem) => (sum + elem, len + 1 )case (k, v) =>List (k, average(v.map(_.age)), v.map(_.id).mkString("," )) "\t\t" )).mkString("\n" )
再从 SQL 的角度来看,在进行 GROUP BY 操作后,会得到上图的结果,被 GROUP BY 的字段不是原子的,这并不符合 SQL 的要求,因此必须要使用某种手段将这字段集合“聚集”到一起,形成单个值。这种聚集手段一般来说是聚集函数。
之前学习 SQL 的时候就没有掌握这里……总的来说,GROUP BY 操作实际上就是构造这样的表,KEY 以外的字段(即 VALUE)不是原子的,需要进行某种“聚集”操作,将它变成原子的。
对应的 SQL 为——
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 DROP TABLE IF EXISTS student_t;CREATE TABLE student_t (INT (10 ) PRIMARY KEY,INT (10 ),VARCHAR (32 ),INT (10 )INSERT INTO student_t VALUES 0 , 101 , "king halo", 15 ),1 , 101 , "haru urara", 14 ),2 , 101 , "seiun sky", 16 ),3 , 102 , "tokai teio", 15 ),4 , 102 , "special week", 16 ),5 , 103 , "silence suzuka", 16 ),6 , 104 , "amami haruka", 17 ),7 , 104 , "kisaragi chihaya", 17 );select class_id, AVG (age), GROUP_CONCAT(id) FROM student_t GROUP BY class_id;
对比 SQL 和 Scala 的操作,能够发现两者基本是一致的——它们的行为是:(首先按 Where 进行筛选操作!)首先按标识符分组,然后相当于是创建了一张仅有两个字段的临时表,其中第一个字段为标识符,第二个字段为对应该标识符的实体的集合,这时候的任务就变成了对每个标识符对应实体的集合进行“聚集”(reduce 操作;众所周知,reduce 操作可以实现 map 操作),构造一个原子的值或列簇。
GROUP BY 子句和 聚集函数 考虑这样的需求,我们需要知道每 月航班准时到达或起飞的比例,知道每 月航班取消或改道比例等,像这种需求,就是要求把数据按特定字段(如日期,编号,性别等)进行分组,对每一组分别进行聚集操作 ,从而能够获取特定于该字段上下文的特定信息,比如“每个月的航班数量”,“每个姓氏的数量”,“每个班级的人数”……
直接从一个例子开始,我们需要从原始数据中获取到这些信息——
月份
该月航班数量
准时到达的比例
到达延迟的比例
准时起飞的比例
延迟起飞的比例
取消的比例
改航的比例
考虑到原始数据的结构,我们需要从原始数据的结构中取出如下信息,即 Mappser 部分——
航班的月份
航班到达延迟时间(为 0 的认为没有延迟)
航班起飞延迟时间(同上)
是否取消
是否改航
这里只有 SELECT 操作,没有 WHERE 操作,获取这样的数据对应的 SQL 为——
SELECT month , arrDelay, depDelay, canceled, diverted FROM airline_t;
这样得到的数据是每个航班的数据,并非是按月分组的数据,因此我们先加上GROUP BY——
SELECT month , arrDelay, depDelay, canceled, diverted FROM airline_t GROUP BY month ;
按 month 分组后,arrDelay,depDelay,canceled,diverted 这四个字段就不是原子的了,需要使用聚集函数,而具体如何进行聚集呢?这由业务决定 (废话)。
再次考虑需求,可以看到,我们要做的主要是要统计每个月的航班数量,以及准时到达的数量,准时起飞的数量,取消的数量,改航的数量,然后就能够计算上面的所有比例了,容易得到下面的 SQL——
SELECT month ,COUNT (1 ) AS airline_count,COUNT (arrDelay = 0 OR NULL ) / airline_count AS arrive_in_time,1 - arrive_in_time AS arrive_delay,COUNT (depDelay = 0 OR NULL ) / airline_count AS dep_in_time,1 - dep_in_time AS dep_delay,COUNT (canceled = 1 OR NULL ) / airline_count AS is_canceled,COUNT (diverted = 1 OR NULL ) / airline_count AS is_divertedFROM airline_t GROUP BY month ;
下面,开始编写相应的 Mapper 和 Reducer,同时尽可能减少输出的数据长度。
关于 Mapper 的编写,目前有三种考虑——
只做简单的映射操作,将相应字段取得即可。
根据问题背景,设置输出的 KV 对格式为<Text, IntWritable>,其中 K 为月份,V 为按二进制位对特定状况进行标识的一个数字,如(从右往左数)第一个 bit 为 1 时,则到达延误,第二个 bit 为 1 时则出发延误,第三个 bit 表示航班取消,第四个 bit 表示航班改航。
将各个延误情况区分开,比如 9 月某个航班既出发延误,又到达延误,则向上下文中写入三个 KV 对,分别标识一条记录(任何航班都会插入该条),一条出发延误记录,一条到达延误记录,("09", 0),("09", 1),("09", 2)
记录即 KV 对。
第一种方法……字面意思,有一些完全没有必要的信息(如具体的延误时间)发送给了 Reducer,比较浪费;第二种方法需要的网络 IO 较少,但实现比较麻烦;第三种方法实现最为方便,但网络 IO 较多,这里使用第三种方法。
但最大的问题是,这三种方案都无法使用 Combiner 或者需要另外定义 Combiner。应当使用一个集合类型如 ArrayWritable 作为 Mapper 的输出值。这待后面谈到 Combiner 时再说。
优化前的 AggregationMRJob 见此,之后的示例里就不写 Driver 了,顶多提及一下重要配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 import org.apache.hadoop.fs.Path import org.apache.hadoop.io.{IntWritable , LongWritable , Text }import org.apache.hadoop.mapreduce.{Job , Mapper , Reducer }import org.apache.hadoop.mapreduce.lib.input.{FileInputFormat , TextInputFormat }import org.apache.hadoop.mapreduce.lib.output.{FileOutputFormat , TextOutputFormat }import org.apache.hadoop.util.GenericOptionsParser import java.langclass AggregationMapper extends Mapper [LongWritable , Text , Text , IntWritable ] override def map LongWritable , value: Text , context: Mapper [LongWritable , Text , Text , IntWritable ]#Context ): Unit = {import AirlineCol ._if (value.toString.startsWith("Year" )) {return val colGetter = AirlineCol .build(value.toString.split("," ))def padLeft String , len : Int , c : Char ) : String =val month = padLeft(colGetter(Month ), 2 , '0 ')val arrDelay = colGetter(ArrDelay ).toIntOption.getOrElse(0 )val depDelay = colGetter(DepDelay ).toIntOption.getOrElse(0 )val isCancelled = colGetter(Cancelled ) == "1" val isDiverted = colGetter(Diverted ) == "1" new Text (month), new IntWritable (0 ))if (arrDelay > 0 ) {new Text (month), new IntWritable (1 ))if (depDelay > 0 ) {new Text (month), new IntWritable (2 ))if (isCancelled) {new Text (month), new IntWritable (3 ))if (isDiverted) {new Text (month), new IntWritable (4 ))class AggregationReducer extends Reducer [Text , IntWritable , Text , Text ] override def reduce Text , values: lang.Iterable [IntWritable ], context: Reducer [Text , IntWritable , Text , Text ]#Context ): Unit = {import scala.jdk.CollectionConverters .IterableHasAsScala val (recordCount, arrDelayCount, depDelayCount, cancelCount, divertCount) =0.0 , 0.0 , 0.0 , 0.0 , 0.0 )) { (counter, elem) =>match {case 0 => counter.copy(_1 = counter._1 + 1 )case 1 => counter.copy(_2 = counter._2 + 1 )case 2 => counter.copy(_3 = counter._3 + 1 )case 3 => counter.copy(_4 = counter._4 + 1 )case 4 => counter.copy(_5 = counter._5 + 1 )val result = recordCount.toString +"," + List (1 - arrDelayCount / recordCount, 1 - depDelayCount / recordCount, 100 ).toString.take(5 ) + "%" ).mkString("," ) new Text (result))object AggregationMRJob def main Array [String ]): Unit = {val parser = new GenericOptionsParser (args)val inputPath +: outputPath +: _ = parser.getRemainingArgs.toSeq.map(new Path (_))val job = Job .getInstance(parser.getConfiguration)AggregationMRJob .getClassTextInputFormat ]TextOutputFormat [Text , Text ]]Text ]IntWritable ]Text ]Text ]AggregationMapper ]AggregationReducer ]1 FileInputFormat .setInputPaths(job, inputPath)FileOutputFormat .setOutputPath(job, outputPath)System exit {if (job waitForCompletion true ) 0 else 1
得到的数据如下,这里并没有使用标准 CSV 格式,如果使用,则输出的 KEY 应该使用 NullWritable 类型。
01 436950 .0 ,40 .08 %,59 .91 %,54 .54 %,45 .45 %,3 .605 %,0 .527 %02 412579 .0 ,41 .29 %,58 .70 %,56 .87 %,43 .12 %,1 .774 %,0 .305 %03 445080 .0 ,42 .68 %,57 .31 %,57 .95 %,42 .04 %,0 .701 %,0 .237 %04 427325 .0 ,48 .68 %,51 .31 %,62 .74 %,37 .25 %,0 .564 %,0 .248 %05 435916 .0 ,49 .28 %,50 .71 %,62 .35 %,37 .64 %,0 .602 %,0 .245 %06 431299 .0 ,50 .06 %,49 .93 %,61 .60 %,38 .39 %,0 .278 %,0 .216 %07 441118 .0 ,49 .15 %,50 .84 %,60 .36 %,39 .63 %,0 .623 %,0 .329 %08 446769 .0 ,48 .97 %,51 .02 %,60 .69 %,39 .30 %,0 .554 %,0 .281 %09 424075 .0 ,51 .76 %,48 .23 %,67 .38 %,32 .61 %,0 .480 %,0 .190 %10 441670 .0 ,47 .72 %,52 .27 %,63 .27 %,36 .72 %,0 .522 %,0 .186 %11 420861 .0 ,43 .60 %,56 .39 %,58 .38 %,41 .61 %,0 .835 %,0 .249 %12 438454 .0 ,43 .13 %,56 .86 %,56 .86 %,43 .13 %,1 .055 %,0 .308 %
关于 Reducer 每个 Mapper 的结果会按照 KEY 进行排序 和 Shuffle (非常重要),分别发送给不同的 Reducer,Reducer 的输入类型需和 Mapper 的输出类型匹配,每个 Reducer 都将拿到一些 KEY 对应的记录的集合 ,比如 ReducerA 会拿到 KEY 为01,03的记录集合,ReducerB 会拿到02,04的记录的集合(通常不是这样,KEY 会被进行哈希以保证平均)……这里的操作非常重要,之后必须得自己学习。
Mapper 的结果会按 KEY 分发给不同的 Reducer,这是说,特定的 KEY 必定会发送且只发送给一个特定的 Reducer;每一个 Reducer 会接受每个 Mapper 的结果,这是说特定的 Reducer 看到的每一个 KEY,它的 VALUE 会来自每一个 Mapper。
在取得集合后,Reducer 对每个 KEY,都会将其对应的记录集合进行聚集操作,这就是每一次调用 reduce 函数所做的事情。比如,一个 Mapper 的输出结果可能是这样——
01 0... ...
它传递给 Reducer 后,可能变成这样,它本质上和此图结构相同。
01 [0 ,0 ,1 ,2 ,0 ,...] 03 [0 ,1 ,0 ,3 ,0 ,...]
后面的工作就是典型的对集合进行聚集的操作了。需注意的是,它不会一开始就把整个集合全部都加载到内存,那在大数据量大情况下百分百会把内存用完,这也是为什么它传递过来的是一个 Iterable 对象,只允许用户流式地去访问集合。
Reducer 有几个重要的规律/原则——
对每一个 Reducer,每调用一次 reduce 方法,就是处理一个 KEY 对应的记录集合 ,即一个或多个 Mapper 输出的一部分。
对同一个 Reducer,它处理的 KEY 是经过排序的,但 KEY 对应的记录集合默认并不排序 ,运行过程中可能还会发生变化;用户可以自定义二次排序 方法对 VALUE 集合进行排序。
Reducer 之间是不排序的 ,如 ReducerA 可能会拿到 01,03,05,07,09,11 月的 KEY,ReducerB 可能拿到 02,04,06,08,10,12 月的 KEY;Reducer 之间的排序也是可以自定义的。
关于 Combiner 需求解决了,但是这并非是个合适的解决方案——分析输出的日志可以发现平均每一条记录会导致 Mapper 产生两条记录,假设现在有 1 亿条数据,则有 2 亿条记录会被传递给 Reducer。Reducer 通常是无法做到数据本地性的,因此需要 Mapper 将结果通过网络传输给 Reducer,这会造成大量的损耗,而 Combiner 有助于缓解这一问题 。
考虑上面提到的 Mapper 的输出结果,它显然能做优化——有那么多01 0,为啥不能先在本地直接先做一次聚集,然后再传递给 Reducer 呢?这能减少非常大量的 IO(在这个场景下,得有四五个数量级了)!
Combiner 就是服务这样的目的——为每一个 Mapper 的输出在本地预先进行聚集,从而减少网络 IO 。Combiner 使用 Reducer 接口 ,因为其行为也是 reduce。Combiner 的输入要和 Mapper 的输出匹配,输出要和 Reducer 的输入匹配,Combiner 的输入必须和输出一致 。
为什么 Combiner 的输入和输出要一致?因为 Combiner 的调用次数是不确定的,Mapper 的结果可能会经过多次 Combine 操作才最终聚集起来 ,而因此 Combiner 的输出必须要能够作为其它 Combiner 的输入。这和 java8-stream 的 reduce 操作非常类似。
为此,我们必须对 Mapper,Reducer 全部都进行重写以匹配 Combiner 的需求。
这里选择让 Mapper 的输出类似01 [1,0,0,0,0] 01 [1,1,0,0,0]...,Combiner 就合并同样的 KEY,得到01 [1999,888,77,66,55]...,然后 Reducer 再次进行再一次的合并操作,得到最终结果。其实这样的话 Combiner 和 Reducer 的逻辑是基本一样的,差别在于最后的输出不一样。
书上使用 MapWritable,但是是当作 Bean 对象使用的…不知道性能如何。
使用 ArrayWritable 需要注意,如果该类型作为 Reducer 的输入类型,则需要定义其子类并给定空构造函数 ,传递该数组内的 Writable 的 class,因为其在运行时会通过反射创建该类,而默认的 ArrayWritable 不提供空构造函数。
带上 Combiner 的 AggregationMRJob 代码如下。两个坑,第一个是 ArrayWritable 如果有反序列化的需求(如作为 Combiner,Reducer 的输入)的话,必须要继承和编写空构造函数才能用,第二个是Array[IntWritable]不能转换成Array[Writable],Java 的数组不能逆变,协变 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 case class IntArrayWritable (extends ArrayWritable (classOf[IntWritable ] )object IntArrayWritable def apply Array [Writable ]) : IntArrayWritable = {val res = new IntArrayWritable class AggregationMapper extends Mapper [LongWritable , Text , Text , IntArrayWritable ] override def map LongWritable , value: Text , context: Mapper [LongWritable , Text , Text , IntArrayWritable ]#Context ): Unit = {import AirlineCol ._if (value.toString.startsWith("Year" )) {return val colGetter = AirlineCol .build(value.toString.split("," ))def padLeft String , len : Int , c : Char ) : String =val month = padLeft(colGetter(Month ), 2 , '0 ')val arrDelay = colGetter(ArrDelay ).toIntOption.getOrElse(0 )val depDelay = colGetter(DepDelay ).toIntOption.getOrElse(0 )val isCancelled = colGetter(Cancelled ) == "1" val isDiverted = colGetter(Diverted ) == "1" new Text (month), IntArrayWritable (Array (1 , if (arrDelay > 0 ) 1 else 0 , if (depDelay > 0 ) 1 else 0 , if (isCancelled) 1 else 0 , if (isDiverted) 1 else 0 new IntWritable (_))))class AggregationCombiner extends Reducer [Text , IntArrayWritable , Text , IntArrayWritable ] override def reduce Text , values: lang.Iterable [IntArrayWritable ], context: Reducer [Text , IntArrayWritable , Text , IntArrayWritable ]#Context ): Unit = {import scala.jdk.CollectionConverters .IterableHasAsScala val result = values.asScala.map(_.get).foldLeft(Array (0 ,0 ,0 ,0 ,0 )) {(acc, cols) =>IntWritable ].get).zip(acc).map {case (a, b) => a + b}IntArrayWritable (result.map(new IntWritable (_))))class AggregationReducer extends Reducer [Text , IntArrayWritable , Text , Text ] override def reduce Text , values: lang.Iterable [IntArrayWritable ], context: Reducer [Text , IntArrayWritable , Text , Text ]#Context ): Unit = {import scala.jdk.CollectionConverters .IterableHasAsScala val Array (recordCount,arrDelayCount,depDelayCount,cancelCount,divertCount) = values.asScala.map(_.get).foldLeft(Array (0 ,0 ,0 ,0 ,0 )) {(acc, cols) =>IntWritable ].get).zip(acc).map {case (a, b) => a + b}val result = recordCount.toString +"," + List (1 - arrDelayCount / recordCount, 1 - depDelayCount / recordCount, 100 ).toString.take(5 ) + "%" ).mkString("," ) new Text (result))
Partitioner Partitioner 的作用一言以蔽之,就是将 Mapper 的中间结果进行分组,并将同一组的 KV 对发送给同一个 Reducer 处理 ,可以说 Partitioner 是为了负载均衡 。
MR 中默认的 Partitioner 为 HashPartitioner,实现如下。
public class HashPartitioner <K, V> extends Partitioner <K, V> {public int getPartition (K key, V value, int numReduceTasks) {return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
这意味着几件事——
Partitioner 默认根据 KEY 的哈希值来进行分区,和 VALUE 无关,但可以自定义 Partitioner 使在分区时利用上 VALUE
一定的 KEY 一定会发送给一定的 Reducer
如果自定义 Bean 作为 Reducer 的 KEY,应当实现 hashCode,以保证同一个 KEY 一定发送给同一个 Reducer,不然的话默认按内存地址作为哈希值,相等的两个 KEY 可能会发送给不同的 Reducer,这会导致错误结果,比如对于 WordCount 程序,可能在输出中会出现hello 93 ... hello 194,出现了多个同样的 KEY,这结果是不符合预期的。
getPartition 应当是纯函数(是如此吗?)
但 Partitioner 仍然在有时候有自定义的需求,比如,对于那些淡季旺季差别很明显的数据呢?考虑分析每月旅游业的一些数据,在 5 月至 10 月是旅游业的旺季,数据量非常大,特别是 5 月,10 月,和其它月份可能有上十倍的差距,而其他时间就是淡季。
这时候,HashPartitioner 是无法起到“负载均衡”的作用的,不同 Reducer 因为分到的月份不同,因此得到的数据量就有可能有很大差异,因而执行时间就会有差异,造成一定的资源浪费,这时候就非常适合根据业务需求自定义 Partitioner。
再比如,当我们想要让每个组生成独立的文件的时候,我们也可以自定义自己的 Partitioner,这时一般 Partitioner 和 ReduceTask 数量耦合。
需注意,Partitioner 的泛型为 Mapper 的输出类型 (当然,也是 Combiner 的输出类型)。
栗子 考虑将每个月的航班数据分离成独立的文件,从而能够方便对每月数据进行进一步分析这个需求,这里就很适合自定义 Partitioner。
首先,在 Driver 类中,需要指明 ReduceTask 的数量以及 Partitioner,根据需要,这里应当指定为 12 个——
job.setNumReduceTasks(12 )MonthPartitioner ])
自定义的 Partitioner 特别简单,将第 n 月分给第 n 个 Reducer 即可,注意 Reducer 的索引从 0 开始——
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class MonthPartitioner extends Partitioner [Text , Text ] override def getPartition Text , value: Text , numPartitions: Int ): Int =1 class SplitByMonthMapper extends Mapper [LongWritable , Text , Text , Text ] override def map LongWritable , value: Text , context: Mapper [LongWritable , Text , Text , Text ]#Context ): Unit = {if (value.toString.startsWith("Year" ))return val colGetter = AirlineCol .build(value.toString.split("," ))val month = colGetter(AirlineCol .Month )new Text (month), value)class SplitByMonthReducer extends Reducer [Text , Text , NullWritable , Text ] override def reduce Text , values: lang.Iterable [Text ], context: Reducer [Text , Text , NullWritable , Text ]#Context ): Unit = {NullWritable .get, _))
编写完成后进行运行,能看到输出文件夹下有 12 个结果文件,每个结果文件包含一定月的数据,如 00000 为 1 月,00001 为 2 月,00011 为 12 月,这种映射是不会改变的。但是每个结果文件内的数据并不有序 。
该需求不需要 Combiner。
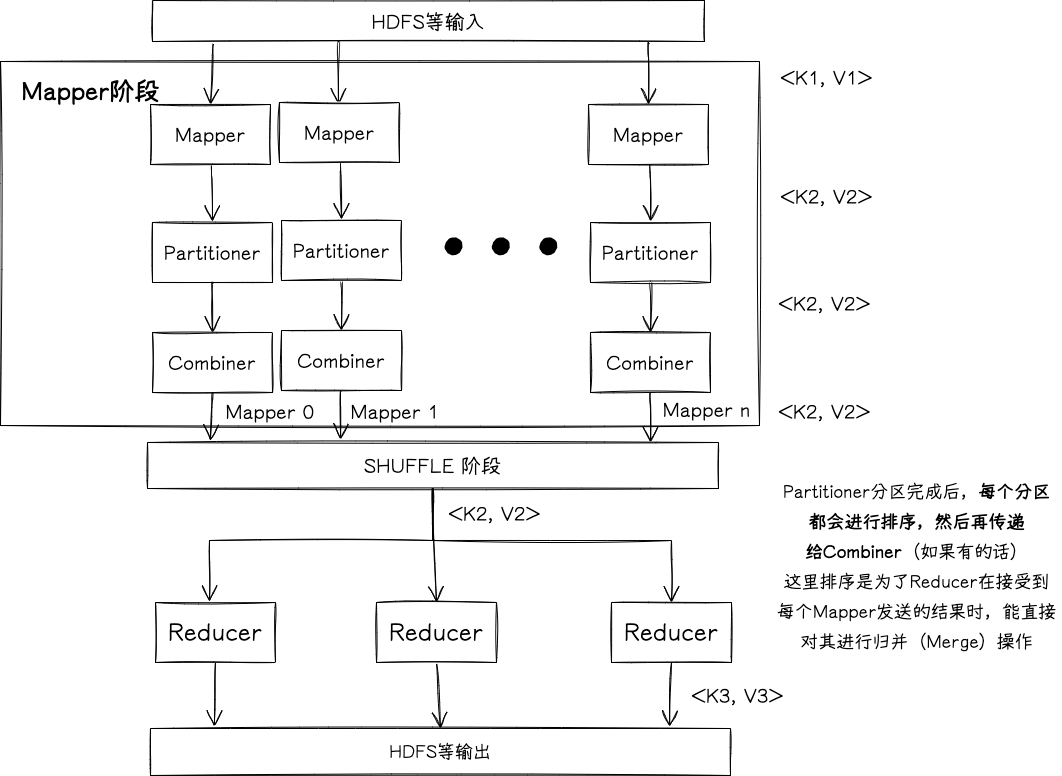
MapReduce Perspective 一张图了事,细节之后再议。这里一个需要注意的地方是,Partitioner 的执行是在 Combiner 之前 (这问题网上争论不一啊……经我本地的测试,确实是 Partitioner 先执行),所以是先分区,然后排序,然后再本地合并。
为啥是这样呢?我猜测是因为排序之后 Combine 操作才好进行,容易对每个 KEY 都并行,顺序地执行 Combine 操作 (CPU 缓存友好?);如果不排序的话就需要维护每个 KEY 的索引列表了,可能实现会更复杂些?这个过程在内存中进行,所以我认为这和硬盘是否顺序读写无关。